Kapitel8 TGDI


(:requiretuid:)
Einführung in TGDI – Kapitel 8
Autoren: Anna Wenzelburger, Moritz Fischer, Patrick Meyn
Einleitung
Die Rechenleistung eines Systems hängt von 2 Dingen ab:
- Der Prozessorleistung
- Der Leistung des Speichersystems
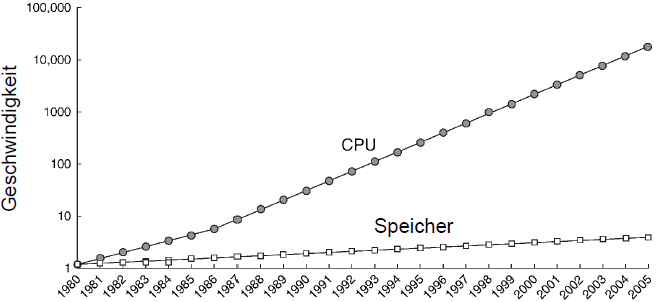
Bisher haben wir stets angenommen, dass Speicherzugriffe konstant einen Takt benötigen, dies ist jedoch schon seit ca den 1980' Jahren nicht mehr der Fall. Da die Prozessorgeschwindigkeit deutlich schneller anstieg als die Speichergeschwindigkeit gibt es heute einen gravierenden Unterschied.
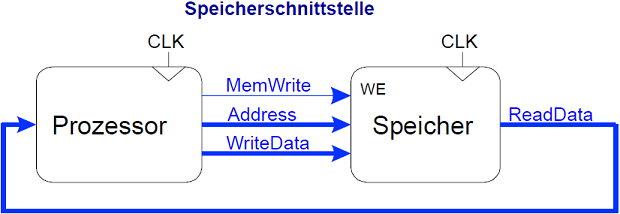
Entwurf eines Speichersystems
Der Grundgedanke eines Speichers mit der selben Geschwindigkeit wie der Prozessor ist jedoch geblieben, zumindest in der Form das die Arbeit mit dem Speicher sich zumindest gleich schnell anfühlen soll.
Im Idealfall würde sich ein solcher Speicher durch 3 Eigenschaften kennzeichnen:
- Schnell
- Billig
- Hohes Fassungsvermögen
In der Praxis lassen sich jedoch nur jeweils 2 der 3 gewünschten Eigenschaften realisieren. Daher hat man sich statt des idealen Speichers auf das Verwenden mehrerer verschiedener Speicher in einer Hierarchie verlegt.
Speicherhierarchie
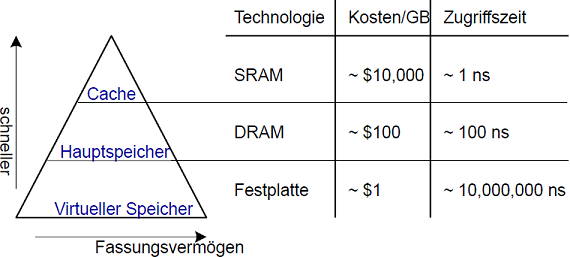
Die Idee dahinter ist nach außen hin als ein großer Speicher zu erscheinen, intern aber verschiedene Stufen zu haben. Ganz oben steht der Cache, ein kleiner aber sehr schneller Typ von Speicher. Darunter liegt der deutlich größere aber auch deutlich langsamere Hauptspeicher, sowie der noch größere und langsamere virtuelle Speicher auf der Festplatte.
Ein Zugriff von außen auf den Speicher wird zuerst auf den Cache geleitet, und optimalerweise liegen dort die gewünschten Daten. Da der Cache sehr schnell arbeitet, werden die gewünschten Daten auch schnell zurückgeliefert. Erst wenn der die Daten nicht im recht kleinen Cache gefunden werden können, wird in der nächsten Stufe der Hierarchie gesucht.
Lokalität
Bei dem hierarchischen Speichersystem ist also durch eine intelligente Verwaltung der Position an der Daten gespeichert werden möglich, eine schnelle Zugriffsgeschwindigkeit zu realisieren, obwohl teils sehr langsame Speichermedien verwendet werden. Eine wesentliche Methode zur Beschleunigung der Speicherzugriffe ist das Ausnutzen von Lokalität
Zeitliche Lokalität:
- Ein gerade benutztes Datum wird vermutlich in absehbarer Zeit wieder benötigt
- Ausnutzung: Gerade verwendete Daten in höheren Ebenen der Hierarchie halten
Räumliche Lokalität:
- Um ein benutztes Datum herum liegende Daten werden vermutlich ebenfalls bald benötigt
- Ausnutzung: Beim Zugriff auf ein Datum auch benachbart liegende Daten auf eine höhere Hierarchieebene bringen
Zugriffszeit eines Speichersystems
- Treffer (Hit): Datum wird auf der aktuellen Ebene der Hierarchie gefunden
- Fehlschlag (Miss): Datum wurde nicht gefunden, es muss auf der nächsten Stufe gesucht werden.
- Hit-Rate: = #Hits / #Speicherzugriffe = 1 - Miss Rate
- Miss-Rate (MR): = #Misses / #Speicherzugriffe = 1 - Hit Rate
Durchschnittliche Speicherzugriffszeit (average memory access time, AMAT): Die durchschnittliche Zeit die es braucht bis der Prozessor das angeforderte Datum erhält.
AMAT = tcache + MRcache (tMM + MRMM * tVM)
MM = main memory, Hauptspeicher
VM = virtual memory, Virtueller Speicher
Beispiel: Zugriffszeitberechnung
Annahmen:
- Speicherhierarchie besteht nur aus Cache/Hauptspeicher
- 2000 Speicherzugriffe
- 1250 Daten im Cache gefunden (Rest im Hauptspeicher
- tcache = 1 Takt
- tMM = 100 Takte
Daraus folgt: Hit-Ratecache = #Hits / #Zugriffe = 1250 / 2000 = 0.625 Miss-Ratecache = 1 - Hit-Rate = 1 - 0.625 = 0.375
AMAT = tcache + MRcache tMM = 1 + 0.375 * 100
= 38.75 Takte
Cachespeicher
- Höchste Ebene der Speicherhierarchie
- Schnell (Erreichen oft die gewünschte 1 Takt Zugriffszeit)
- Stellt dem Prozessor idealerweise die meisten benötigten Daten zur Verfügung
- Speichert (i.d.R.) die zuletzt genutzten Daten
Im Aufbau von Caches gibt es 3 grundsätzliche Entwurfsentscheidungen, die es abzuwägen gilt.
- Welche Daten werden im Cache gehalten
- Wie werden Daten gefunden
- Wie werden Daten ersetzt
Im Idealfall müsste der Cachespeicher vorausahnen, welche Daten der Prozessor als nächstes abfragen wird, das ist in der Praxis jedoch nur sehr ungenau möglich. Die Vorhersage basiert auf dem bisherigen Verhalten des Prozessors und der bereits angesprochenen Lokalität
- Zeitliche Lokalität: Kopiere gerade verwendete Daten in den Cache (falls nicht schon vorhanden)
- Räumliche Lokalität: Kopiere auch benachberte Daten in den Cache (Nachfolgend geregelt durch die Blockgröße)
Begriffe und relevante Größen
Kapazität (Capacity C): Anzahl der im Cache speicherbaren Bytes.
Blockgröße (Blocksize b): Anzahl der auf einen Satz im Cache geladenen Bytes
Blockanzahl (B): Anzahl von Blöcken im Cache. B = C/b
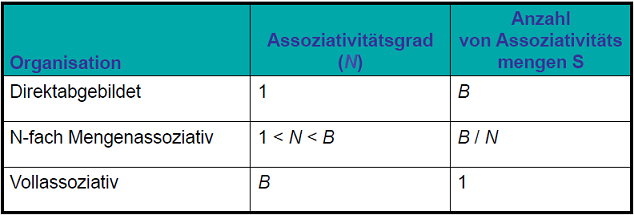
Assoziativgrad (degree of associativity N): Anzahl von Blöcken in einer Assoziativmenge (kurz Menge oder Set)
Anzahl von Assoziativmengen (S = B / N): Jede Speicheradresse wird auf genau eine Assoziativmenge abgebildet
Klassifizierung von Caches
Ein Cache ist als S Mengen (bzw Sets) organisiert, wobei jede Speicheradresse auf genau ein solches Set abgebildet wird.
Dabei werden die Cachespeicher nach der Anzahl an Blöcken in einer Menge klassifiziert:
- Direktabbildend (direct mapped): Ein Block pro Set
- N-Fach Mengenassoziativ (N-way set associative): N Blöcke je Set
- Vollassoziativ (fully associative): Alle Blöcke des Caches in einer Menge
Folgend jeweils Beispielorganisationen für einen Cache mit
- Kapazität C = 8 Worte
- Blockgröße b = 1 Wort
- Blockanzahl (dementsprechend) B = 8
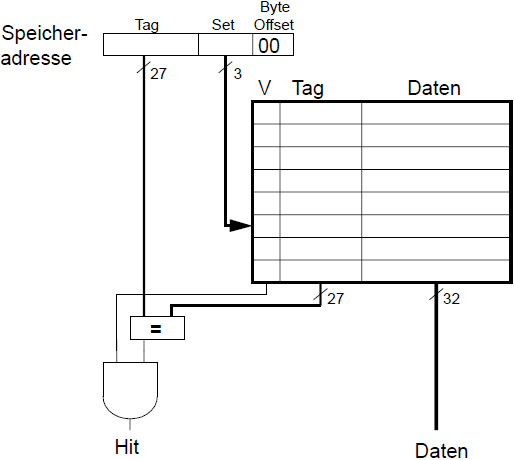
Direktabbildender Cache
Beim direktabbildenden Cache hat jedes Set genau einen Block, bei insgesamt 8 Blöcken gibt es also 8 Sets. Jede Speicheradresse wird dabei auf genau ein solches Set abgebildet. Da es allerdings deutlich mehr Speicheradressen als Sets gibt, werden stets eine Vielzahl von Speicheradressen auf das gleiche Set abgebildet, aber dazu später bei Konflikten mehr.
Eine solche Speicheradresse wird dabei in 3 Abschnitte unterteilt. Tag-Bits, Set-Bits und Byte-Offset (in dieser Reihenfolge). Set-Bits dienen zur Identifizierung des Sets, auf das die Speicheradresse abgebildet wird. Da wir in diesem Beispiel mit 8 Sets arbeiten, brauchen wir also 3 Setbits. Der Byte-Offset ist abhängig von der Art und Weise, wie Worte gehandhabt werden. Wir verwenden hier durchgängig 2 Bits für diesen. Die Tag-Bits hingegen dienen der Identifizierung von Zugehörigkeiten. Wie bereits angegeben werden mehrere Speicheradressen auf das gleiche Set abgebildet, also reichen die Set-Bits nicht aus. Der Tag wird mit in den Cache geschrieben, und nur wenn die Tag-Bits im Cache mit denen der Speicheradresse übereinstimmen, gibt es einen Hit. Eine 32 Bit Speicheradresse mit 3 Set-Bits und 2 Byte-Offset Bits hat also 32 - 3 - 2 = 27 Tag Bits. Für die einzelnen Sets gibt es ebenfalls eine feste Unterteilung der Bits. Jedes Set besteht aus einem Valid-Bit, einer Reihe von Tag-Bits sowie den Datenbits. Das Valid-Bit Gibt an, ob der Eintrag im Set überhaupt zulässig ist. Die Tag-Bits müssen mit den Tag-Bits der abgefragten Speicheradresse übereinstimmen und die Daten-Bits enthalten die im Cache gespeicherten Daten. In unserem Beispiel arbeiten wir mit 32 Bit Daten, der Tag ist 27 Bit lang und 1 Valid-Bit ergibt insgesamt eine Länge von 60 Bit für ein solches Set. Trotzdem beträgt die Speicherkapazität nur 32 Bit pro Set, der Rest dient der Speicherorganisation. Das ist ein wichtiger Unterschied!
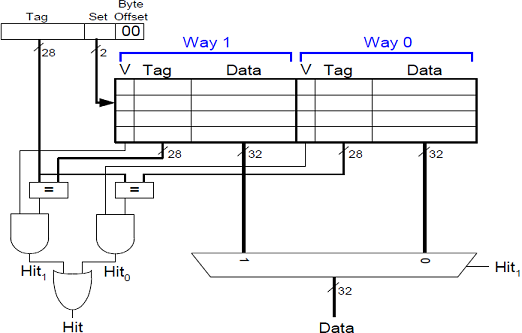
N-Fach Mengenassoziativer Cache
Bei diesem Cachetyp enthält jedes Set N Blöcke von Valid/Tag/Daten Bits. Im Falle von N = 2 gibt es in unserem Beispiel also 4 Sets a 2 Blöcke um die insgesamt 8 Blöcke unterzubringen. Da sich die Anzahl an Sets halbiert hat, reduziert sich auch die Anzahl der Set-Bits, die bei der Speicheradresse nötig sind, von 3 auf 2. Damit gibt es nun 28 statt 27 Tag-Bits.
Wenn nun eine Speicheradresse angesprochen wird, so können die gewünschten Daten in allen N Blöcken des jeweiligen Sets stehen. Es wird also auch weiterhin jede Speicheradresse auf genau ein Set abgebildet, aber es gibt innerhalb jedes Sets Platz für N Einträge. Damit müssen bei jedem Zugriff eben auch N Blöcke überprüft werden, was die Hardware ein Stück komplizierter macht.
Vollassoziativer Cache
Beim vollassoziativen Cache gibt es nur 1 Set, in das alle Einträge geschrieben werden. Damit entfallen die Set-Bits komplett und es gibt keine Konflikte da Daten überall in den Cache geschrieben werden können. Diese Art von Cache ist allerdings extrem teuer in der Herstellung.

Räumliche Lokalität im Cache
Für das berücksichtigen von räumlicher Lokalität gilt es, die Daten in der unmittelbaren Nähe des gewünschten Datums mit in den Cache zu schreiben. Um dies zu realisieren wird die Blockgröße erhöht.
Ein direktabbildender Cache mit einer Kapazität von 8 Worten und einer Blockgröße von 4 Worten hat also 2 Blöcke in 2 Sets.
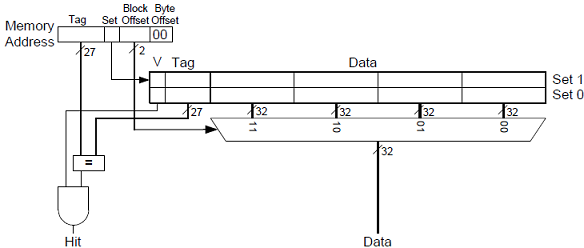
Die Speicheradresse hat nun einen weiteren Unterteilungsblock bekommen. Zwischen Set und Byte-Offset gibt es nun auch noch den Block-Offset, welcher den Block angbit, auf den innerhalb des Sets zugegriffen werden soll. Bei einem Tag-Bit (für 2 Sets), 2 Block-Offset Bits (für 4 Worte je Block) und 2 Byte-Offset Bits bleiben erneut 27 Bits für den Tag.
Arten von Fehlschlägen
- Compulsory: Die unvermeindlichen Fehlschläge sind jene, die Auftreten wenn die ersten male auf den Speicher zugegriffen und es schlicht noch keine zulässigen Daten im Cache gibt.
Diese Art von Fehlschlägen wird durch eine höhere Blockgröße reduziert. Da im Hinblick auf räumliche Lokalität bei jedem Zugriff zusätzlich die umliegenden Daten mit im Cache gespeichert werden, liegen diese Daten dann im nächsten Schritt bereits vor und müssen nicht erneut geladen werden, sollten sie abgefragt werden.
- Conflict: Konfliktfehler entstehen durch die Abbildung von mehreren Speicheradressen auf das gleiche Set.
Während eine Erhöhung der Assoziativität diese Fehlschlagart verringert (da die Daten mehrerer Speicheradressen in einem Set gespeichert werden können), erhöht eine größere Blockgröße diese Fehlerart.
- Capacity: Kapazitätsfehler entstehen dann, wenn der Cache voll ist und ein alter Wert für einen neuen Wert gelöscht wird, dieser alte Wert aber in einer späteren Abfrage doch wieder benötigt wird.
Eine offensichtliche Möglichkeit zur Reduzierung dieser Fehlerart ist die Vergrößerung des gesamten Caches. Eine etwas kostengünstigere Methode ist die Verwendung einer sinnvollen Ersetzungsmethode. Die 'least recently used' (LRU) Methode ersetzt stets das Datum, welches am längsten nicht mehr angesprochen wurde.
Multilevel Caches
Wir wissen:
- größere Caches reduzieren die Anzahl an Capacity-Misses
- größere Caches sind entweder teurer oder bei gleichem Preis langsamer
Die Lösung: Erneut eine Hierarchie von Caches statt eines einzelnen.
- Level 1: klein und schnell (bspw. 16KB, 1 Takt)
- Level 2: größer und langsamer (bspw. 256KB, 2-6 Takte)
Heutzutage sind es meist noch mehr Level an Caches.
Virtueller Speicher
Diese Art des Speichers soll die Illusion eines größeren Hauptspeichers erfüllen, obwohl Festplatten langsamer (dafür aber billiger) als Hauptspeicher sind. So gesehen ist der Hauptspeicher der Cache für die Festplatte.
- Physikalischer Speicher: DRAM (langsamer, größer, grünstiger als der Cache)
- Virtueller Speicher: Festplatte (langsamer, größer, günstiger als der Hauptspeicher)
Jedes Programm verwendet virtuelle Adressen
- Der gesamte virtuelle Adressraum ist auf der Festplatte gespeichert
- Ein Teil der virtuellen Adressen zeigt auf dem Hauptspeicher
- Die CPU übersetzt virtuelle Adressen in physikalische Adressen
- Fehlende Daten werden von der Festplatte in den Hauptspeicher geholt (Fast wie beim Cache!)
Memory Protection
Jedes Programm hat seine eigene Zuordnung von virtuellen auf physikalische Adressen. Daher können zwei Programme die gleichen virtuellen Adressen verwenden und dabei unterschiedliche Daten (jeweils ihre eigenen) ansprechen. Das zu gewährleisten ist die Aufgabe Memory Protection.
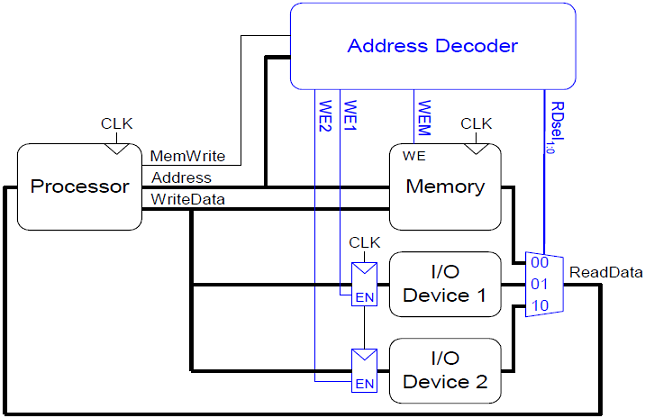
Memory-Mapped Eingabe/Ausgabe Geräte
Der Prozessor kann auf Eingabe/Ausgabe Geräte (Tastaturen, Monitore, Drucker) wie auf Speicher zugreifen. Dazu wird ein Teil des Adressraums für eben diese Geräte reserviert (zB. 0xFFFF0000 bis 0xFFFFFFFF) und jedes Gerät bekommt eine oder mehrere solcher Adressen zugewiesen. Wenn diese Adressen angesprochen werden, werden die entsprechenden Daten aus dem Gerät ausgelesen bzw. auf das Gerät geschrieben. Dazu ist jedoch zusätzliche Hardware erforderlich.
- Address-Decoder: Stellt fest, welches Gerät (oder Speicher) mit der gegebenen Adresse angeprochen wird.
- I/O Register: Speichern Daten aus den Geräten
- ReadDate/WriteData Multiplexer: Wählt zwischen Hauptspeicher und I/O Geräten als Datenquelle für den Prozessor.