Kapitel7 TGDI


(:requiretuid:)
Einführung in TGDI – Kapitel 7
Autoren: Anna Wenzelburger, Moritz Fischer, Patrick Meyn
Einleitung
- Mikroarchitektur
- Prozessor:
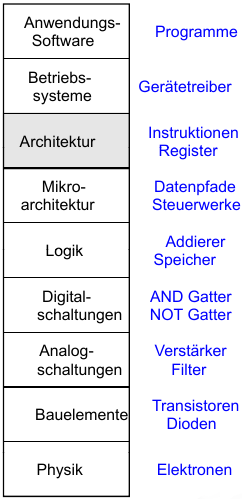
Mikroarchitektur
Mehrere Implementierungen für eine Architektur sind möglich:
- Ein-Takt
- Mehrtakt
- Pipelined
Unser erster MIPS Prozessor
Wir beginnen zunächst mit einer Untermenge des MIPS Befehlssatzes:
- R-Typ Befehle:
and,or,add,sub,slt - Speicherbefehle:
lw,sw - Bedingte Verzweigungen:
beq
Architekturzustand
Die auf Ebene der Architektur sichtbaren, also für die Programmiererin zugänglichen, Daten bestimmen den vollständigen Zustand der Architektur. Diese sind:
PC(program counter)- 32 Register
- Speicher
Elemente des MIPS Architekturzustands
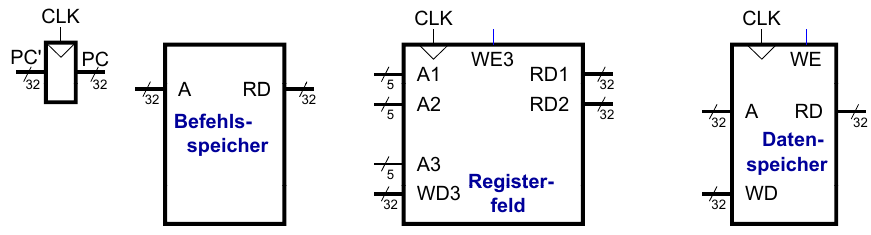
Ein-Takt MIPS Prozessor
Im Folgende erarbeiten wir gemeinsam Datenpfad und Steuerwerk eines Ein-Takt MIPS Prozessors.
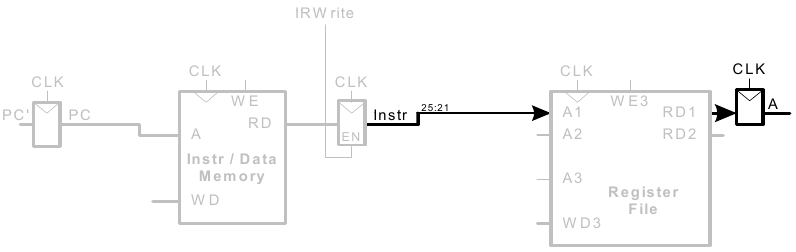
Holen eines lw Befehls
Ein load word Befehl (lw) soll ausgeführt werden.
1. Schritt: Hole Instruktion
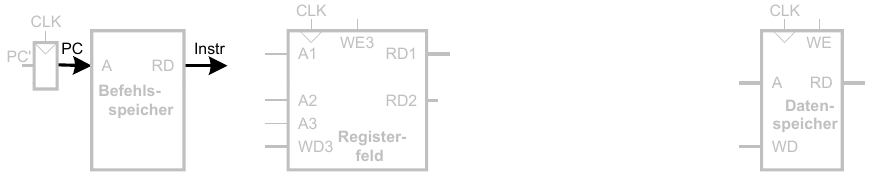
2. Schritt: Lese Quelloperand aus Registerfeld
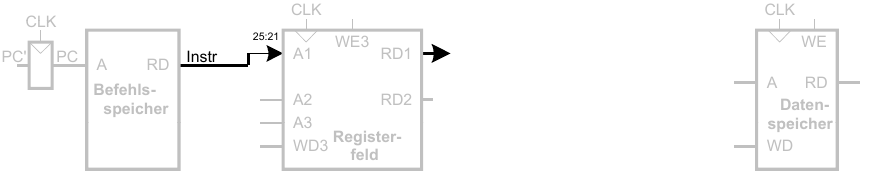
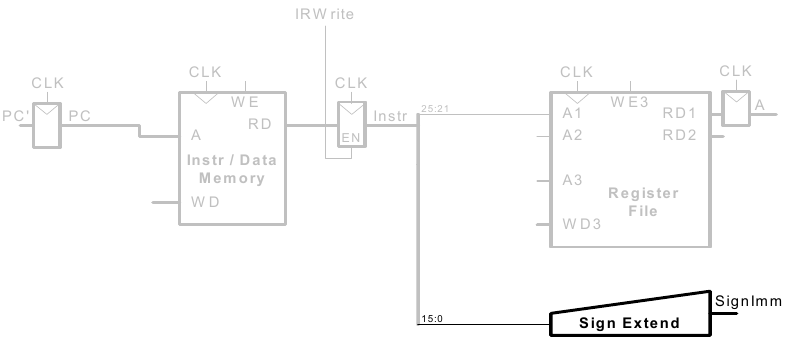
3. Schritt: Vorzeichenerweitere den 16b Direktwert auf 32b Signal SignImm
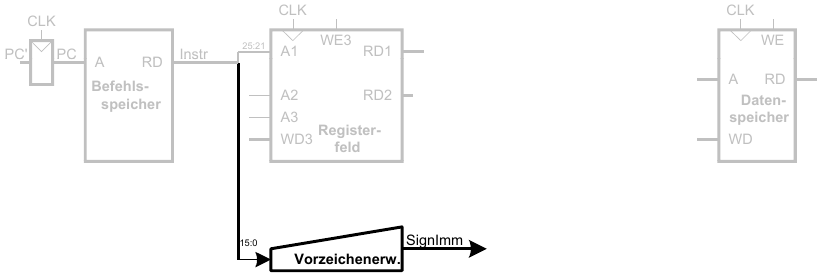
4. Schritt: Berechne die effektive Speicheradresse
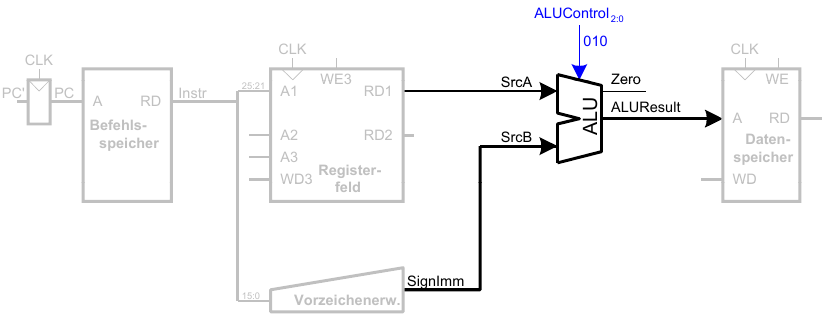
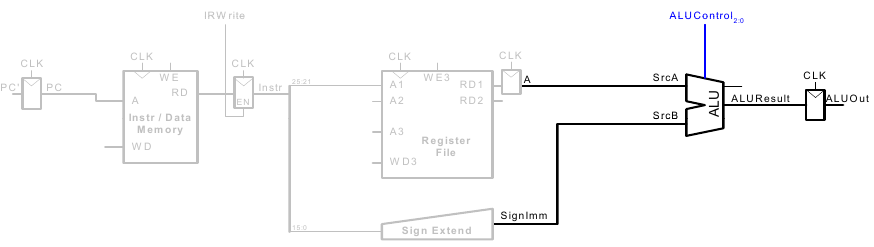
5. Schritt: Lese Daten aus Speicher und schreibe sie ins passende Register
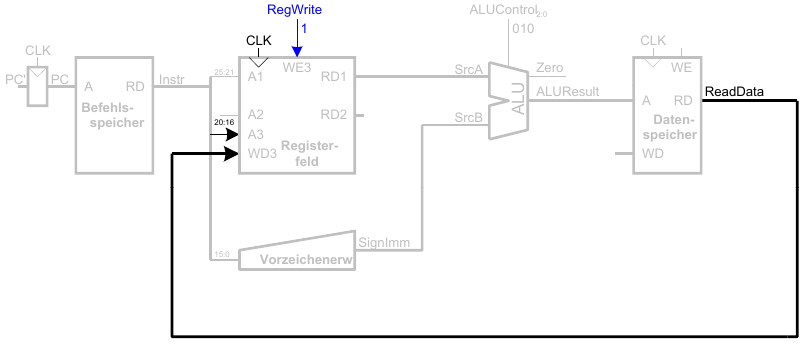
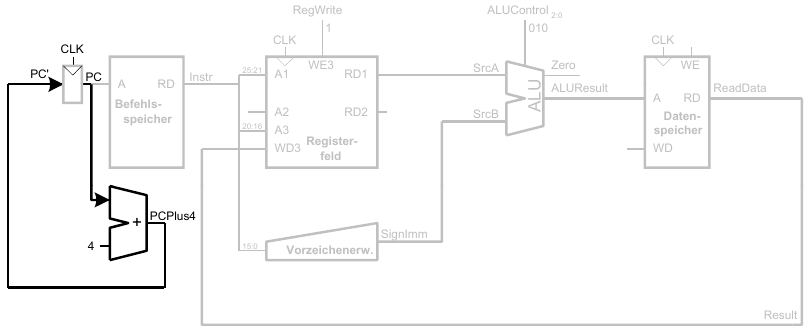
6. Schritt: Bestimme Adresse des nächsten Befehls (Erhöhe PC nach lw)
Ein-Takt Datenpfad: sw
Schreibe Daten aus rt in den Speicher
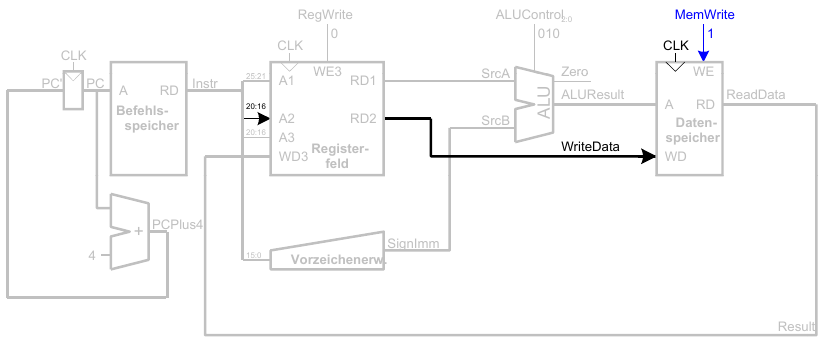
Ein-Takt Datenpfad: Instruktionen vom R-Typ
- Lese aus
rsundrt - Schreibe ALUResult ins Registerfeld
- Schreibe nach
rd(statt nachrtwie beisw)
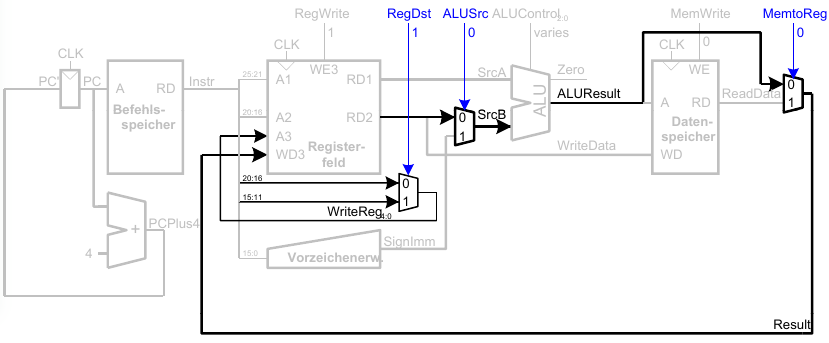
Ein-Takt Datenpfad: beq
- Prüfe ob Werte in
rsundrtgleich sind - Bestimme Adresse von Sprungziel (branch target adress, BTA):
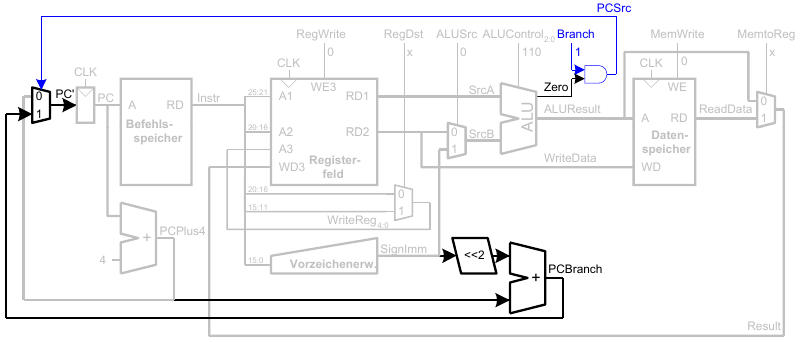
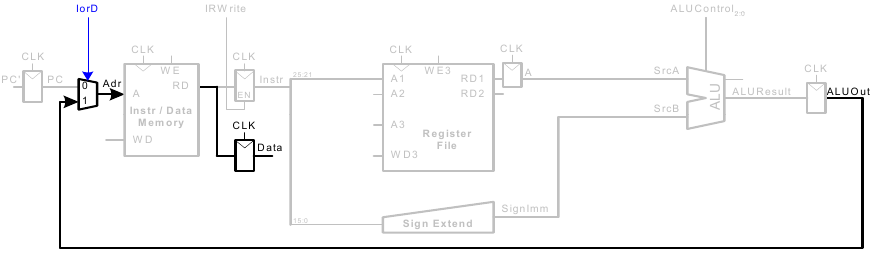
Vollständiger Ein-Takt-Prozessor
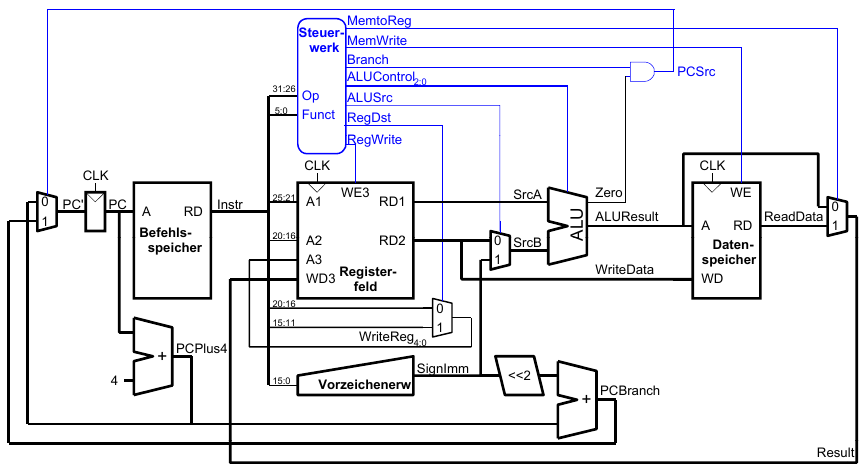
Steuerwerk
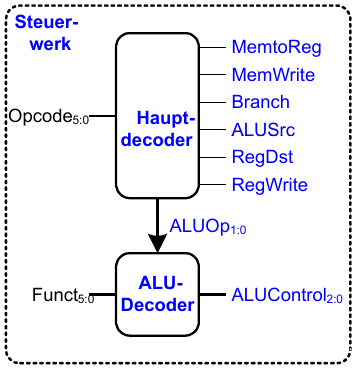
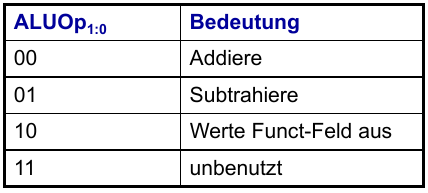
ALU-Decoder
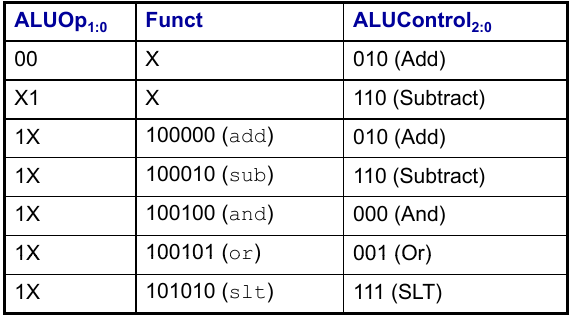
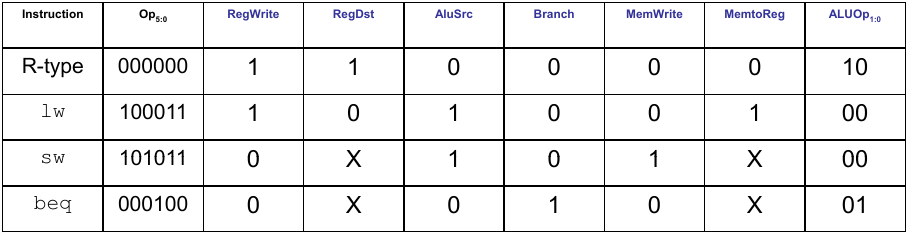
Hauptdecoder
Beispiel im Ein-Takt Datenpfad: or
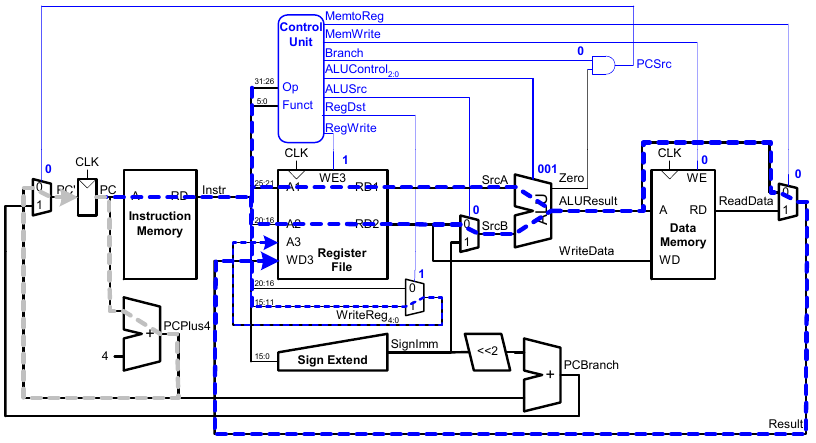
Erweitere Funktionalität: addi
Dazu ist keine Änderung am Datenpfad nötig. Wir erweitern lediglich das Steuerwerk.
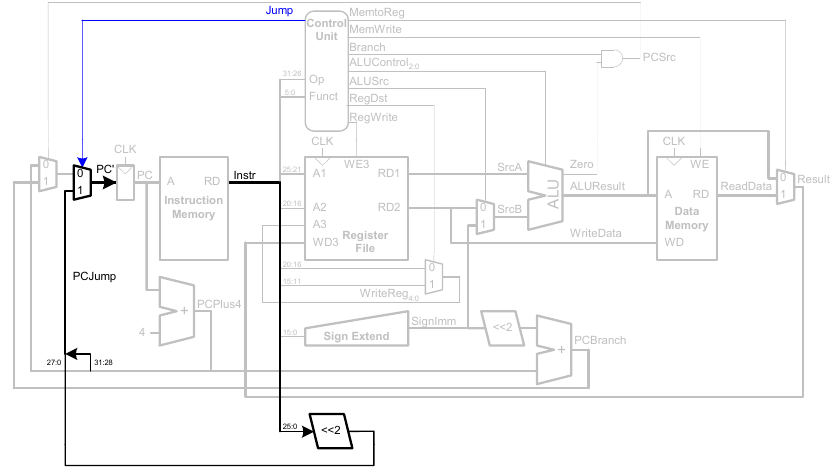
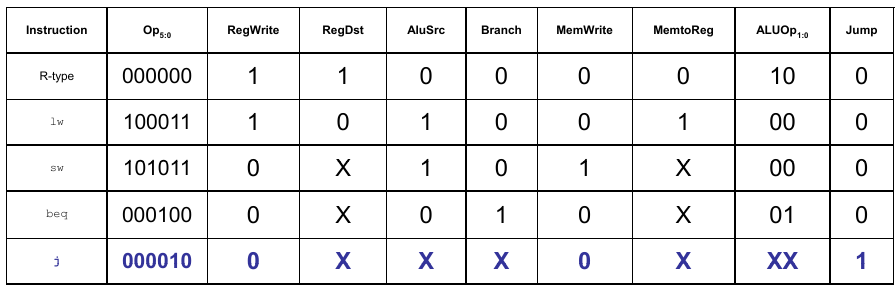
Erweitere Funktionalität: j
Wir müssen den Datenpfad nur geringfügig erweitern, sowie das Steuerwerk an den neuen Befehl anpassen.
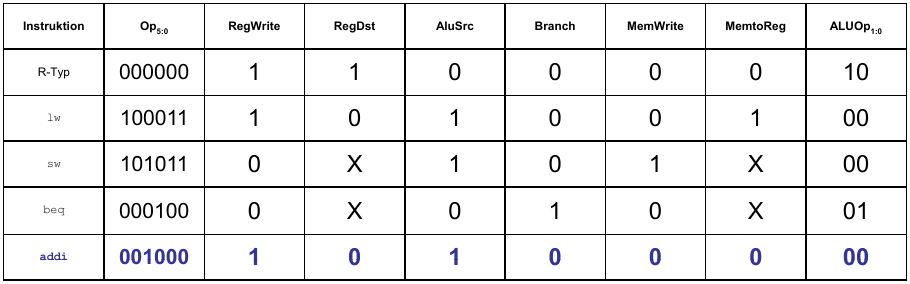
Rechenleistung eines Prozessors
Die Ausführungzeit eines Programms berechnet sich nach folgender Formel.
Ausführungszeit = (# Instruktionen)(Takte/Instruktion)(Sekunden/Takt) = #Instruktionen CPI Tc
- Definitionen:
- Herausforderung: Einhalten zusätzlicher Anforderungen
Rechenleistung des Ein-Takt-Prozessors
Tc wird durch den längsten Pfad bestimmt (lw).
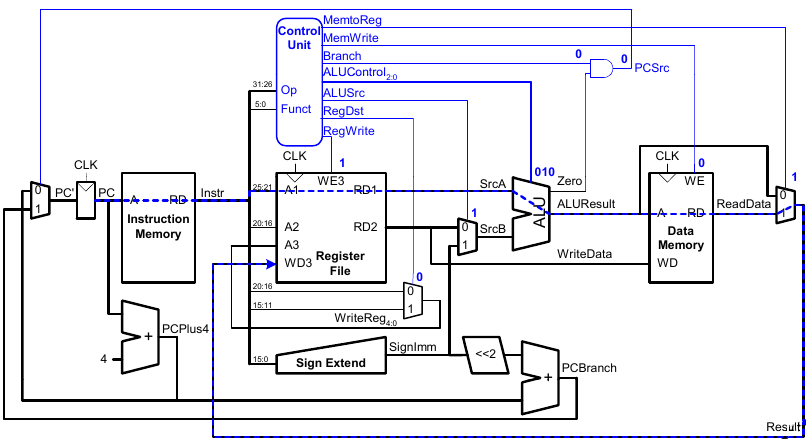
- Kritischer Pfad:
- In vielen Implementierungen: Kritischer Pfad durch Speicher, ALU, Registerfeld
- Damit:
Beispiel
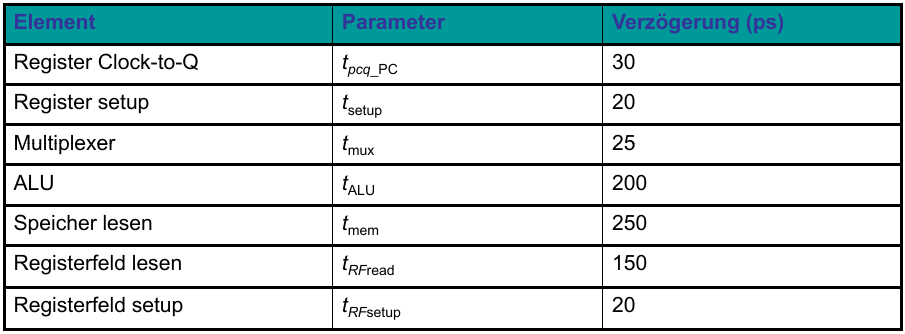
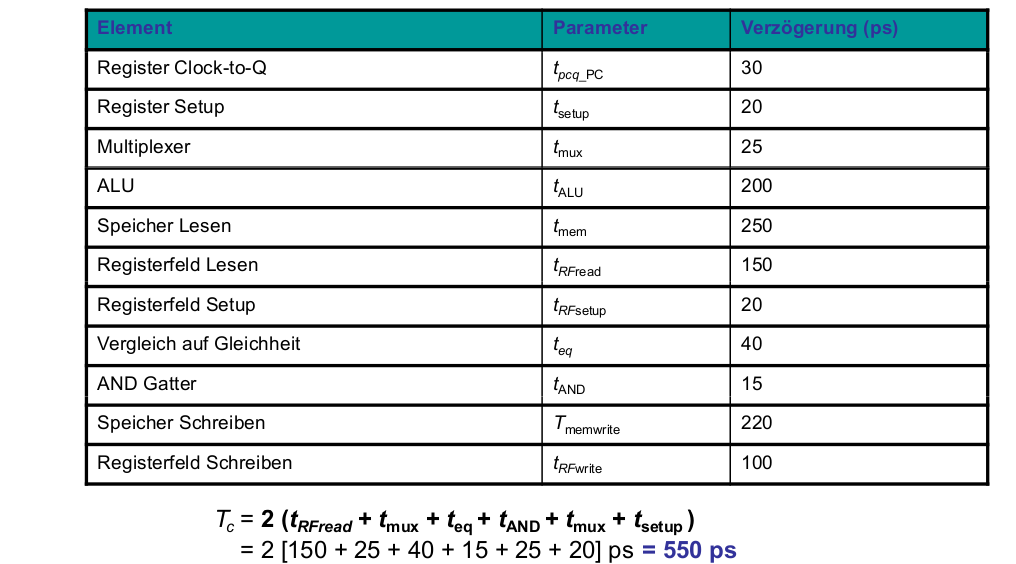
Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU + tRFsetup
Nehmen wir nun an, dass wir ein Programm mit 100 Milliarden Instruktionen auf unserem Ein-Takt MIPS Prozessor ausführen.
Ausführungszeit = #Instruktionen CPI Tc
Mehrtakt-MIPS-Prozessor
- Ein-Takt-Mikroarchitektur:
lw)
- Mehrtaktmikroarchitektur:
- Gleiche Grundkomponenten:
Zustandselemente im Mehrtaktprozessor
Wir ersetzen die getrennten Instruktions- und Datenspeicher (Hardvard-Architektur) durch einen gemeinsamen Speicher (Von Neumann-Architektur). Letztere ist heute weiter verbreitet.
Mehrtaktdatenpfad
Als Beispiel betrachten wir die Ausführung von lw.
Instruktionen holen (fetch)
Lese Register für lw
Werte lw Direktwert ausführen
Bestimme effektive Adresse für lw
Lesezugriff von lw
Schreibe Register in lw
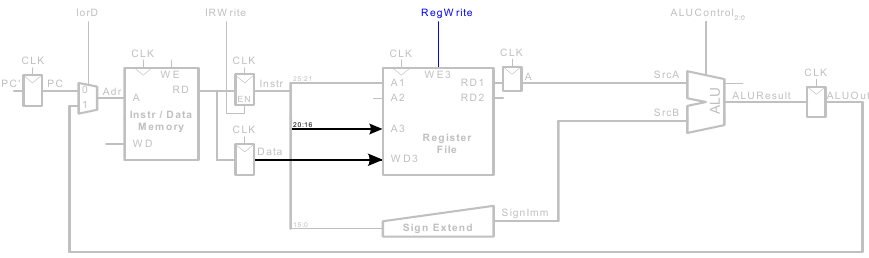
Erhöhe PC
Mehrtaktdatenpfad: weitere Instruktionen
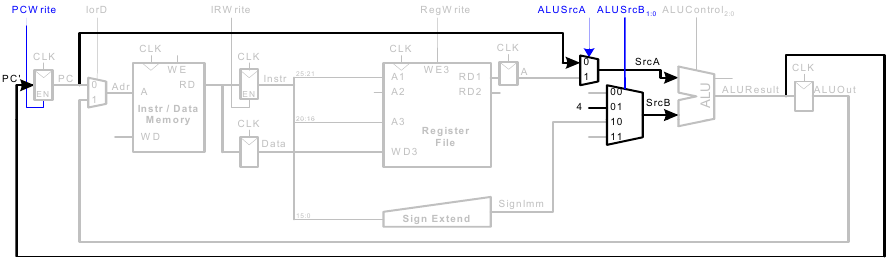
Ausführung von sw
Die Daten aus rt werden in den Speicher geschrieben.
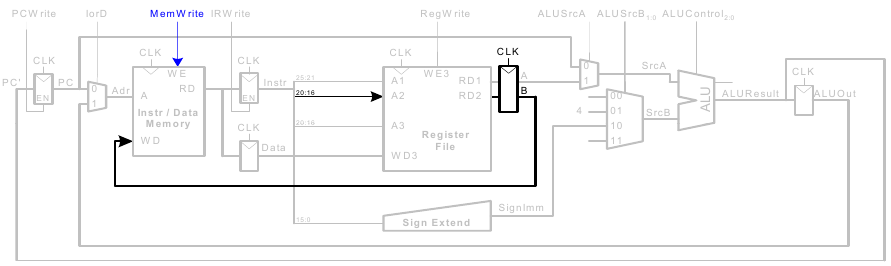
Instruktionen vom R-Typ
- Lese Werte aus
rsundrt - Schreibe ALUResult ins Registerfeld
- Schreibe Wert nach
rd(statt nachrt)
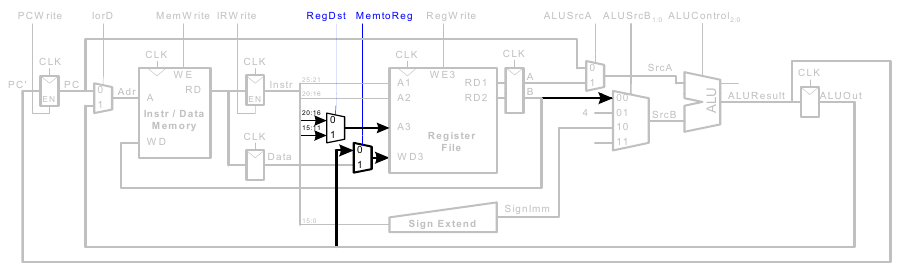
beq-Instruktion
- Prüfe, ob Werte in
rsundrtgleich sind - Bestimme Adresse des Sprungziels (branch target adress):
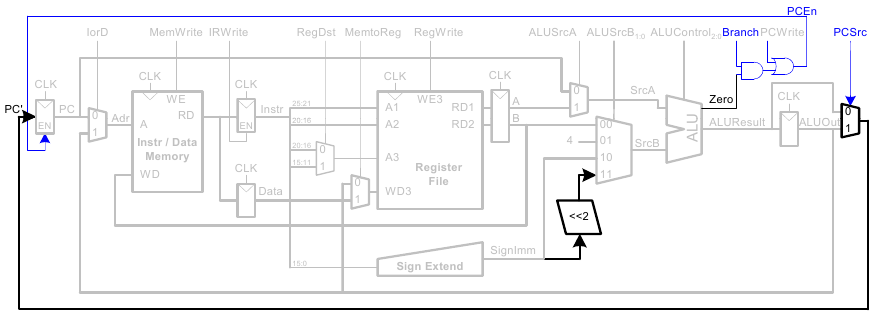
Vollständiger Mehrtaktprozessor
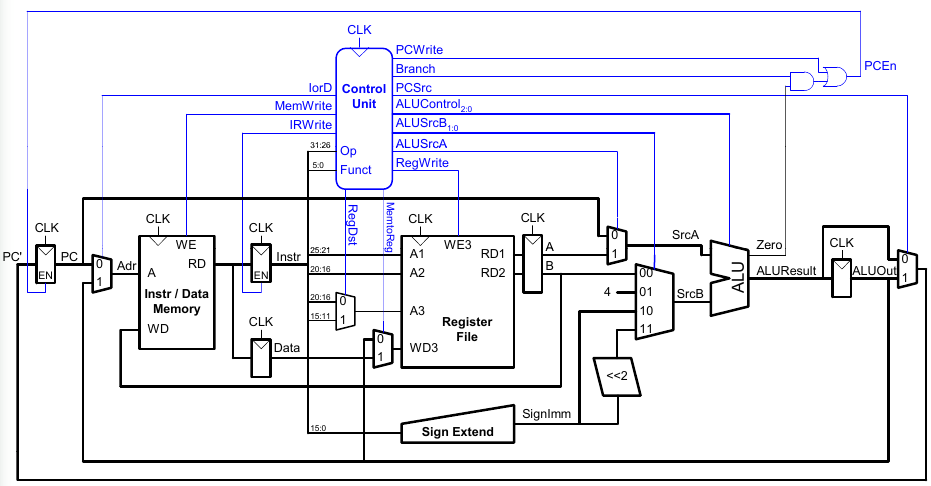
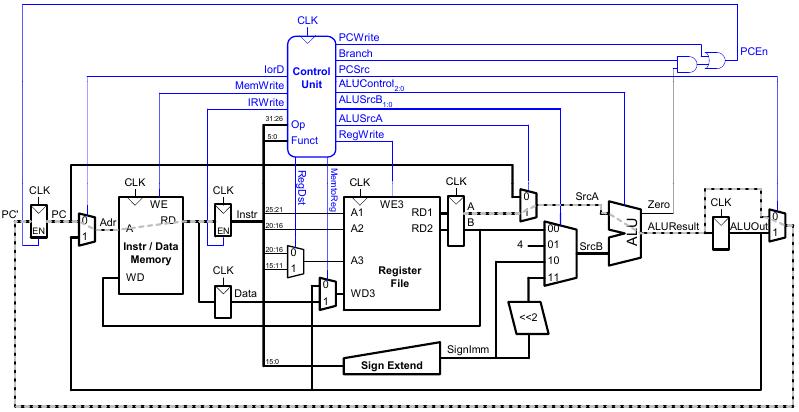
Steuerwerk des Mehrtaktprozessors
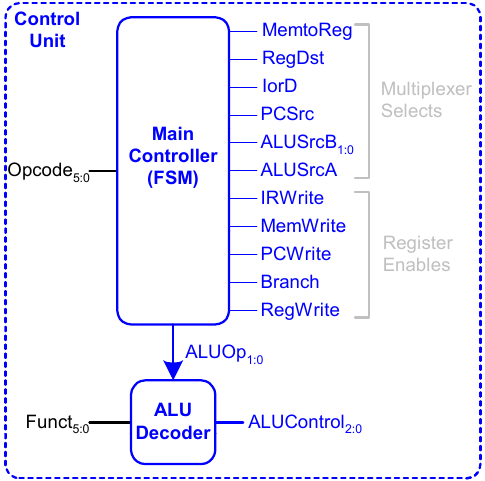
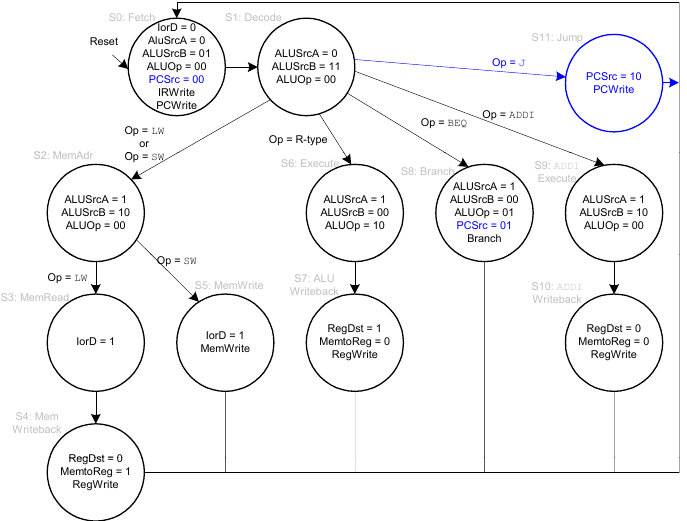
Arbeitsweise des Hauptsteuerwerks
Im Folgenden erarbeiten wir schrittweise die Arbeitsweise des Hauptsteuerwerks.
Holen eines Befehls
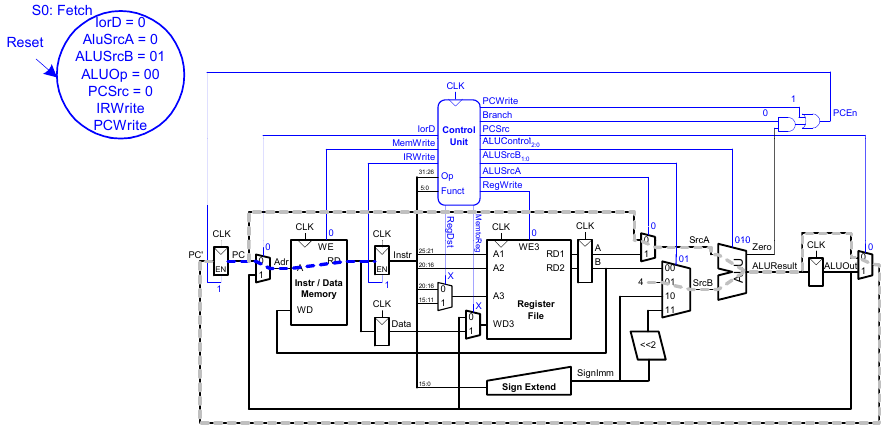
Dekodieren eines Befehls
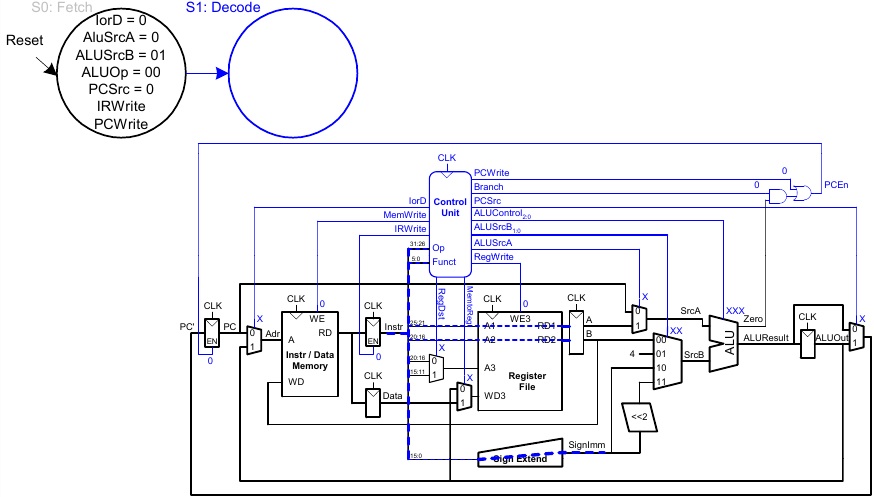
Adressberechnung
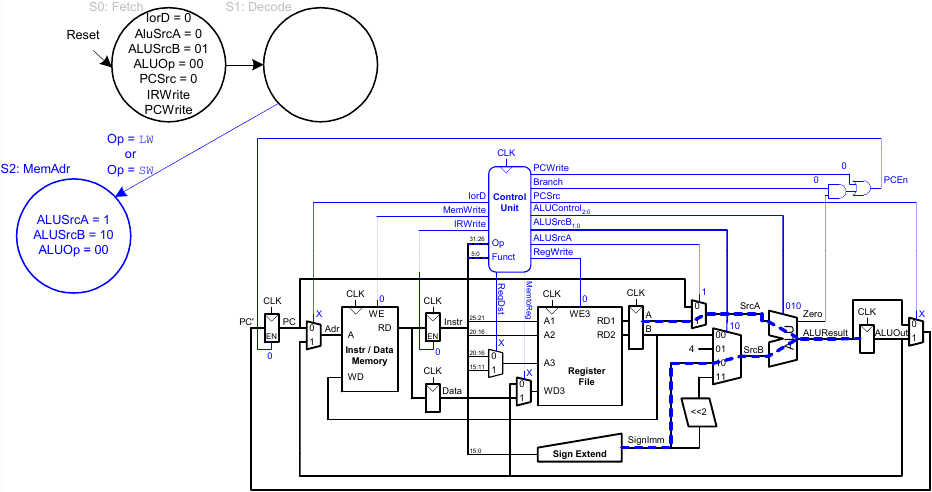
FSM für lw
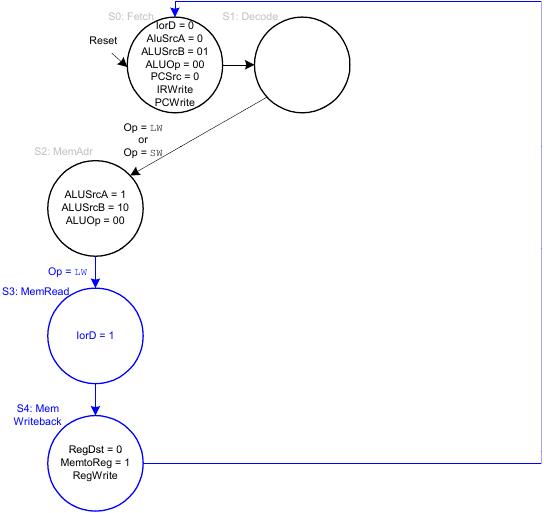
FSM für sw
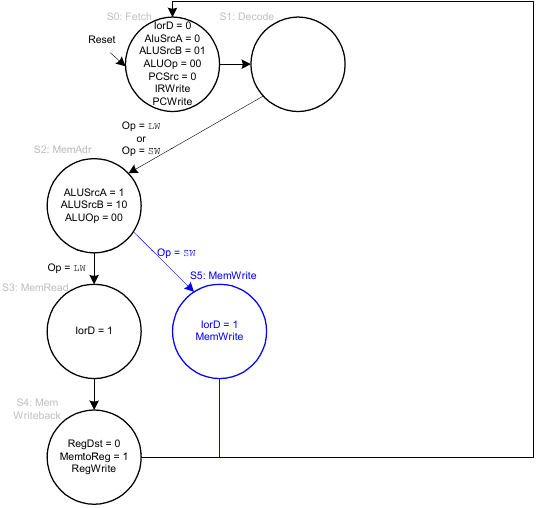
FSM für R-Typ
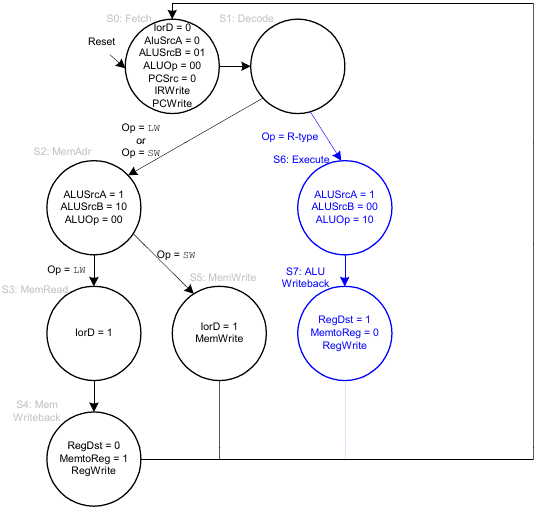
FSM für beq
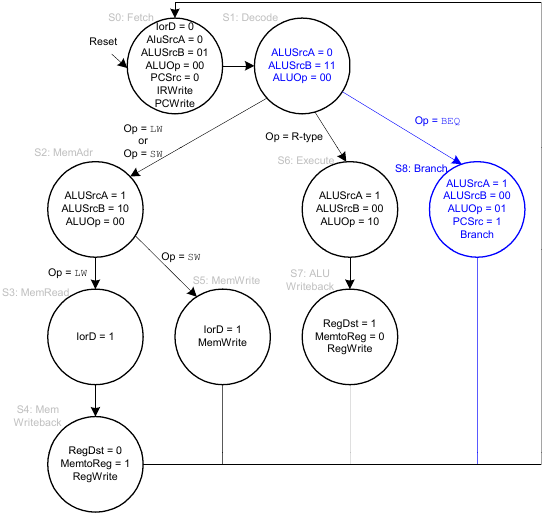
Vollständiges Hauptsteuerwerk für Mehrtakt-CPU
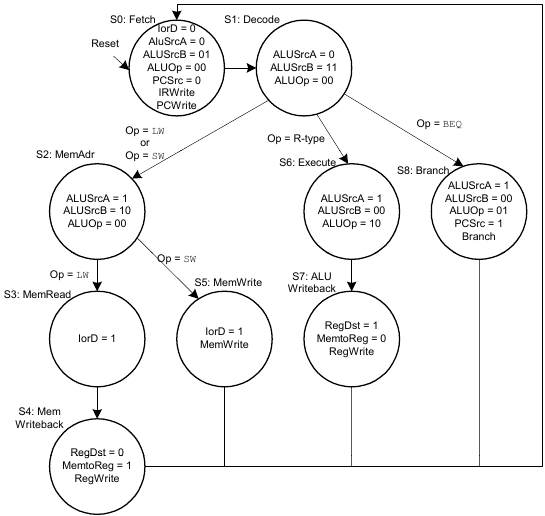
Erweiterungen des Mehrtaktprozessors
Erweiterung des Hauptsteuerwerks für addi-Instruktion
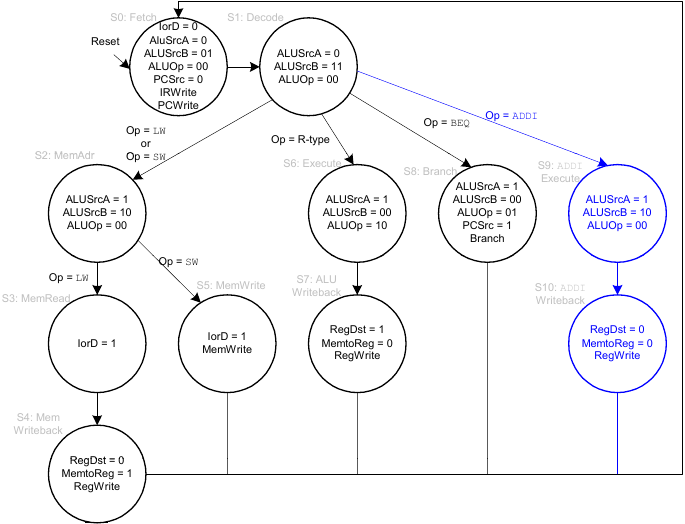
Erweiterung des Datenpfads für j
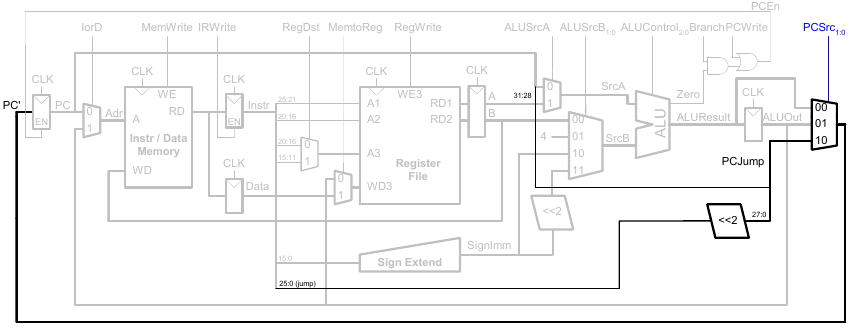
Erweiterung des Hauptsteuerwerks um j
Rechenleistung des Mehrtaktprozessors
In einem Mehrtaktprozessor benötigen die Instruktionen unterschiedlich viele Takte:
- 3 Takte:
beq,j - 4 Takte: R-Typ,
sw,addi - 5 Takte:
lw
CPI wird daher als gewichteter Durchschnitt bestimmt. Der SPECint 2000 Benchmark legt dabei zum Beispiel folgende Gewichtung fest:
- 25% Laden
- 10% Speichern
- 11% Verzweigungen
- 2% Sprünge
- 52% R-Typ
Es ergibt sich also:
Durchschnittliche CPI = (0,11 + 0,02)(3) + (0,52 + 0,10)(4) + (0,25)(5) = 4,12
Kritischer Pfad
Tc = tpcq + tmux + max(tALU + tmux, tmem) + tsetup
Beispiel
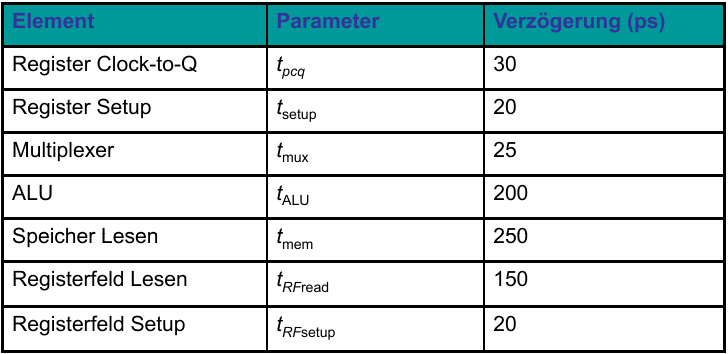
Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) + tsetup
Wir nehmen an, dass ein Programm mit 100 Milliarden Instruktionen auf dem Mehrtaktprozessor ausgeführt wird:
- CPI = 4,12
- Tc = 325 ps
Ausführungszeit = (#Instruktionen) x CPI x Tc
Es fällt auf, dass der Mehrtaktprozessor langsamer ist als der
Ein-Takt-Prozessor (brauchte nur 92,5 Sekunden).
Zwar hat der Mehrtaktprozessor eine unterschiedlich lange Anzahl von Ausführungstakten (bis zu 5 für lw),
aber keine 5-mal schnellere Taktfrequenz. Außerdem gibt es eine zusätzliche Verzögerung für sequentielle Logik
mehrfach je Befehl ( tpcq + tsetup = 50 ps). Dafür ist der Mehrtakt-MIPS-Prozessor
im Hinblick auf die Größe der Hardware potenziell etwas kleiner.
MIPS Prozessor mit Pipelining
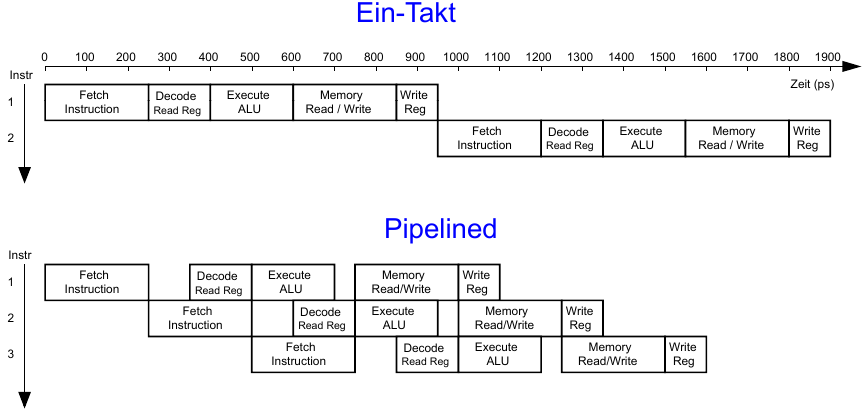
Um den MIPS Prozessor zu optimieren wenden wir das Prinzip der zeitlichen Parallelität an. Dazu teilen wir den Ablauf im Ein-Takt-Prozessor in fünf Stufen:
- Hole Instruktion (Fetch)
- Dekodiere Bedeutung von Instruktion (Decode)
- Führe Instruktion aus (Execute)
- Greife auf Speicher zu (Memory)
- Schreibe Ergebnisse zurück (Writeback)
Um dies umzusetzen fügen wir Pipeline-Register zwischen den Stufen ein.
Rechenleistung: Ein-Takt und Pipelined
Abstraktere Darstellung des Pipelinings
Ein-Takt- und Pipelined-Datenpfad
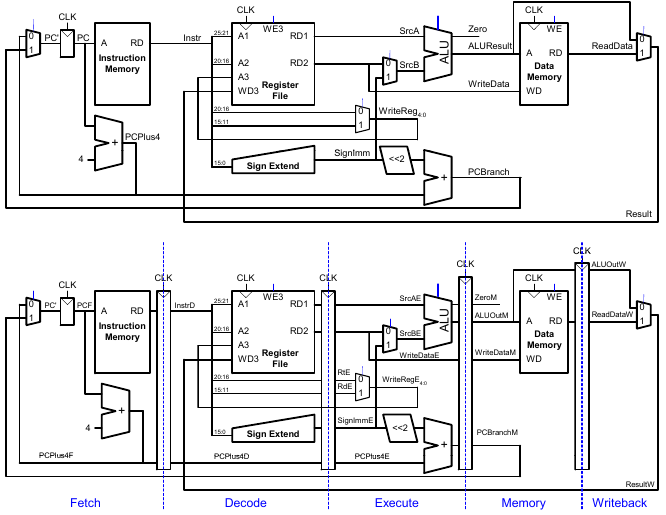
Korrigierter Pipelined-Datenpfad
WriteReg muss zur gleichen Zeit am Registerfeld ankommen wie Result.
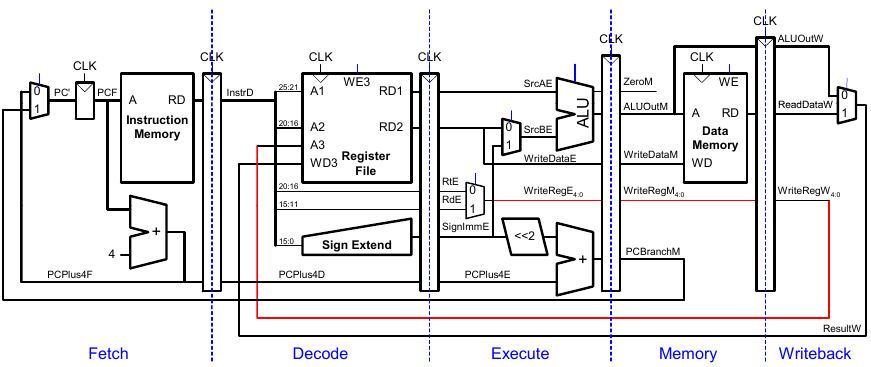
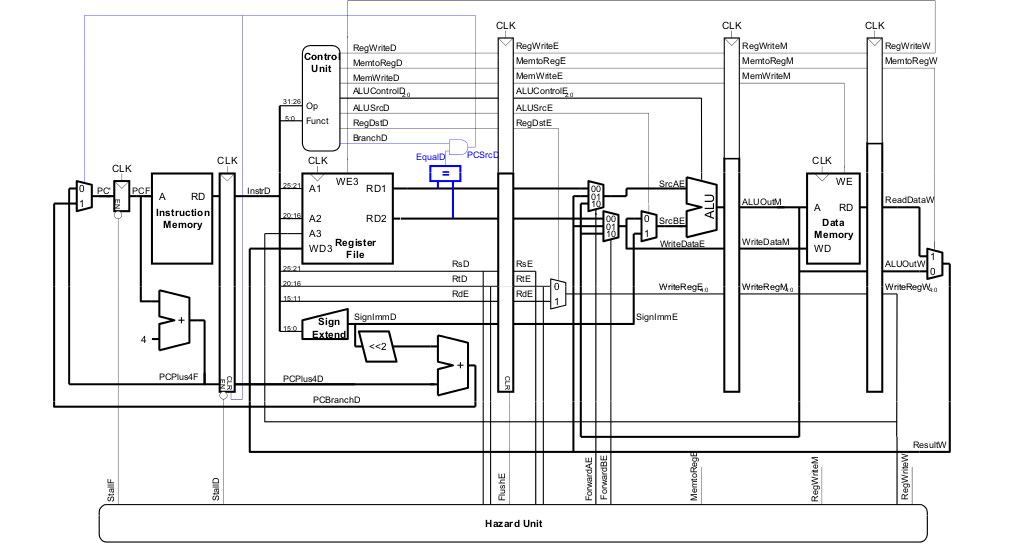
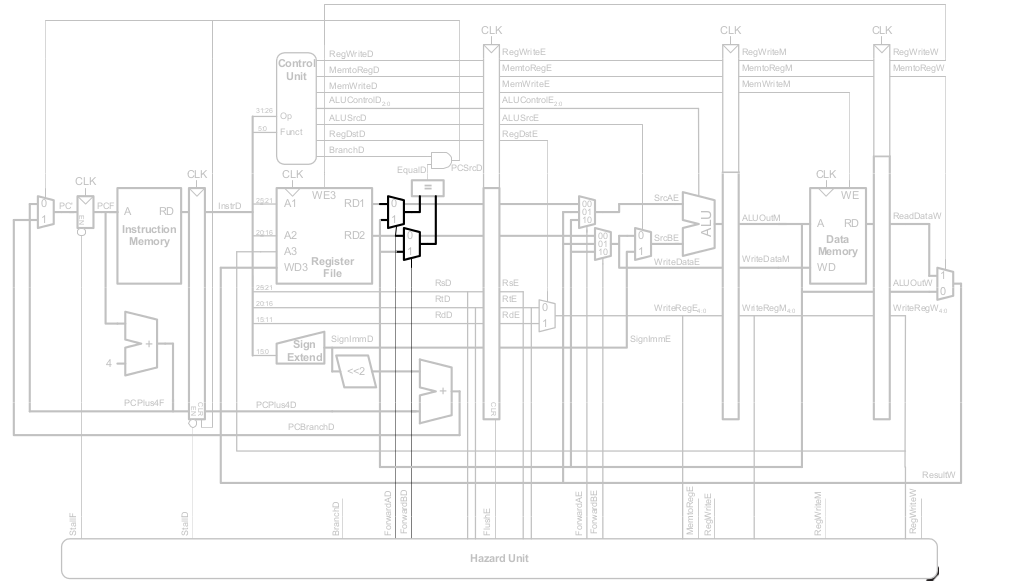
Steuersignale für Pipelined-Datenpfad
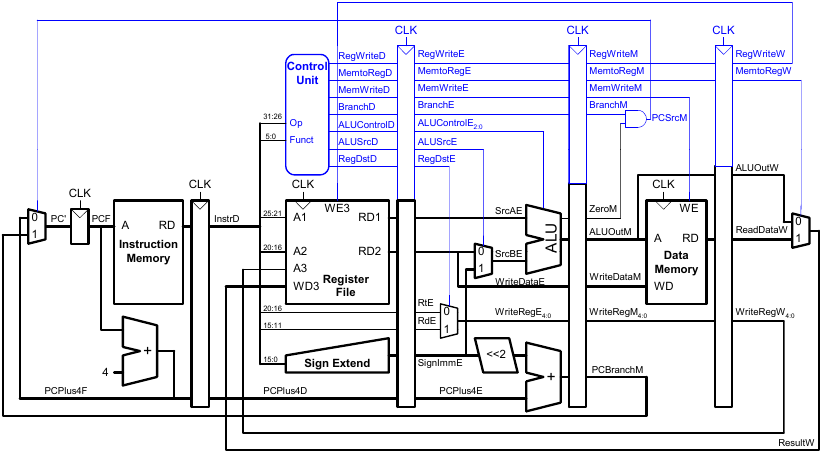
Das Steuerwerk ist identisch zum Ein-Takt-Steuerwerk, aber die Signale werden über die Pipeline-Stufen verzögert.
Abhängigkeiten zwischen Pipeline-Stufen (hazards)
Hazards treten auf, wenn eine Instruktion vom Ergebnis einer vorhergehenden abhängt, diese aber noch nicht kein Ergebnis geliefert hat.
Wir unterscheiden zwei Arten von Hazards:
- Data Hazards: z.B. neuer Wert von Register noch nicht in Registerfeld eingetragen
- Control Hazard: Unklar welche Instruktion als nächstes ausgeführt werden muss; Treten bei Verzweigungen auf
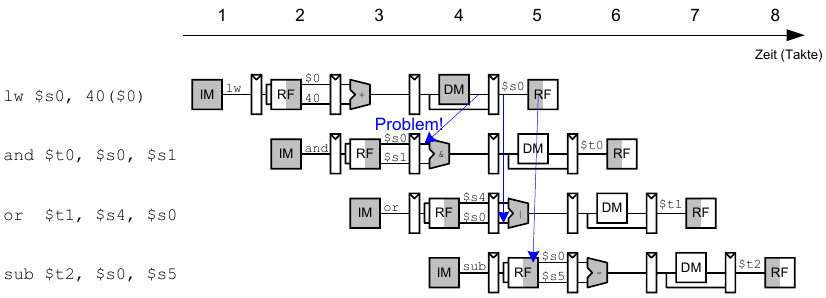
Data Hazards
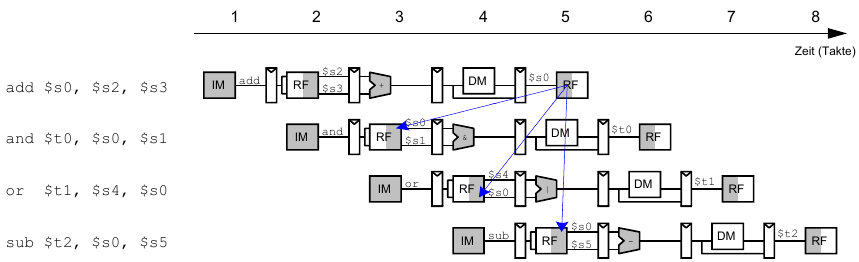
Hier: Read-after-Write Hazard (RAW) - $s0 muss vor dem Lesen geschrieben werden
Umgang mit Data Hazards
Einplanen von Wartezeiten von Anfang an:
- Einfügen von
nops zu Compile-Zeit - scheduling
Umstellen des Maschinencode zur Compile-Zeit
- scheduling / reordering
Schnelleres Weiterleiten der Daten über Abkürzungen zur Laufzeit
- bypassing / forwarding
Anhalten des Prozessors zur Laufzeit bis zur Ankunft der Daten
- stalling
Beseitigung von Data Hazards zur Compile-Zeit
Wir fügen entweder ausreichend viele nops ein bis das Ergebnis bereitsteht oder schieben unabhängige Instruktionen nach vorne (statt nops)
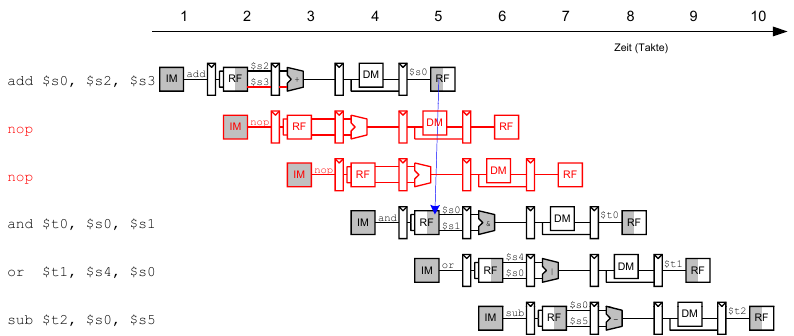
Data Forwarding: Einbauen von "Abkürzungen"
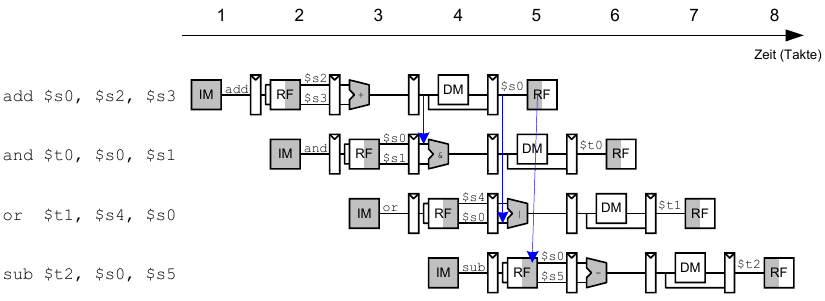
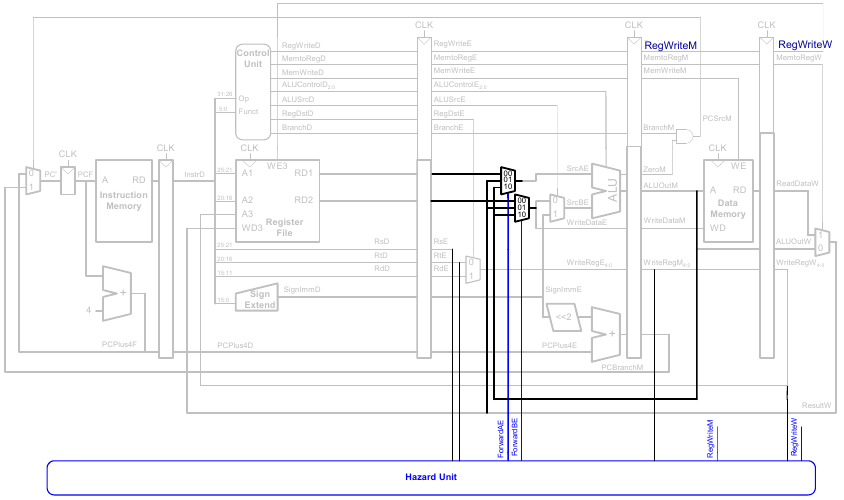
"Abkürzung" zur Execute-Stufe von
- Memory-Stufe oder
- Writeback-Stufe
Forwarding-Logik für Signal ForwardAE(Weiterleiten von Operand A):

Die Forwarding-Logik für das Signal ForwardBE(Weiterleiten von Operand B) funktioniert analog. Wir ersetzen lediglich rsE durch rtE
Anhalten des Prozessors (stalling)
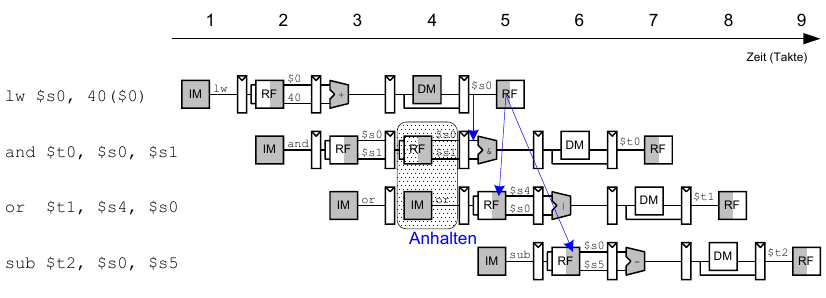
Um stalling zu ermöglichen, müssen wir die Hazard Unit erweitern.
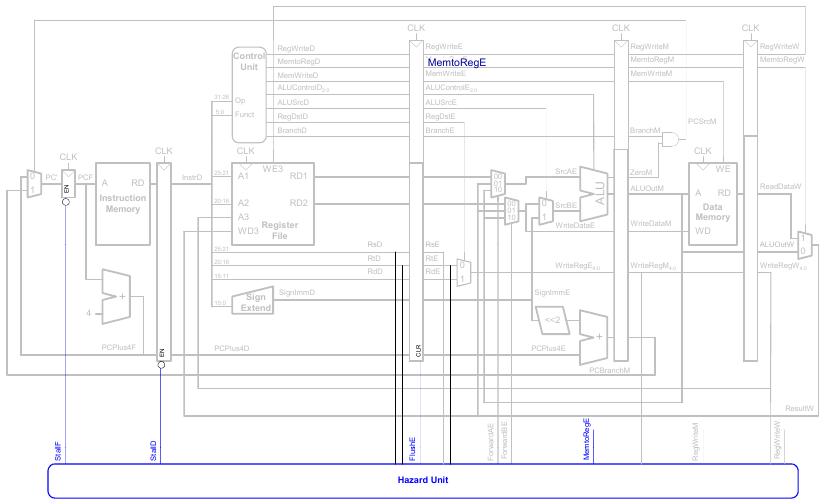
Die Hazard Unit verwendet dabei folgende Logik.

Control Hazards
Control Hazards können bei Verzweigungen auftreten, z.B. bei beq:
- Entscheidung zu Springen wird erst in der vierten Stufe der Pipeline (M) getroffen
- Neue Instruktionen werden aber bereits geholt (im einfachsten Fall von PC+4, +8, +12 usw.)
- Falls zu springen ist, müssen diese Instruktionen aus der Pipeline entfernt werden
Die Kosten eines falsch vorhergesagten Sprunges sind daher die Anzahl von zu entfernenden Instruktionen, falls der Sprung genommen wird. Diese könnten reduziert werden, wenn der Sprung in einer früheren Pipeline-Stufe entschieden würde.
Control Hazards: Ursprüngliche Pipeline
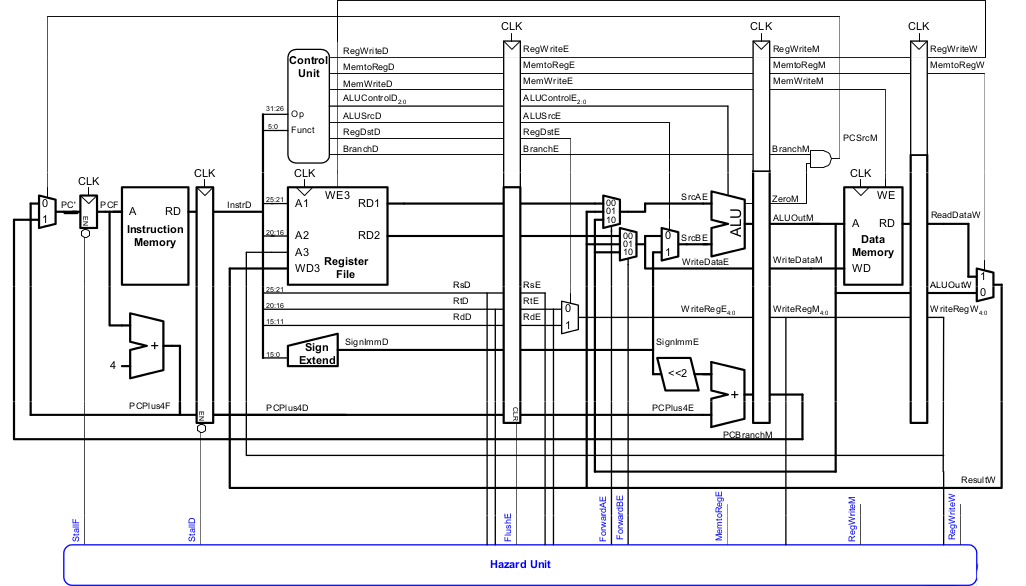
Beispiel: Control Hazard
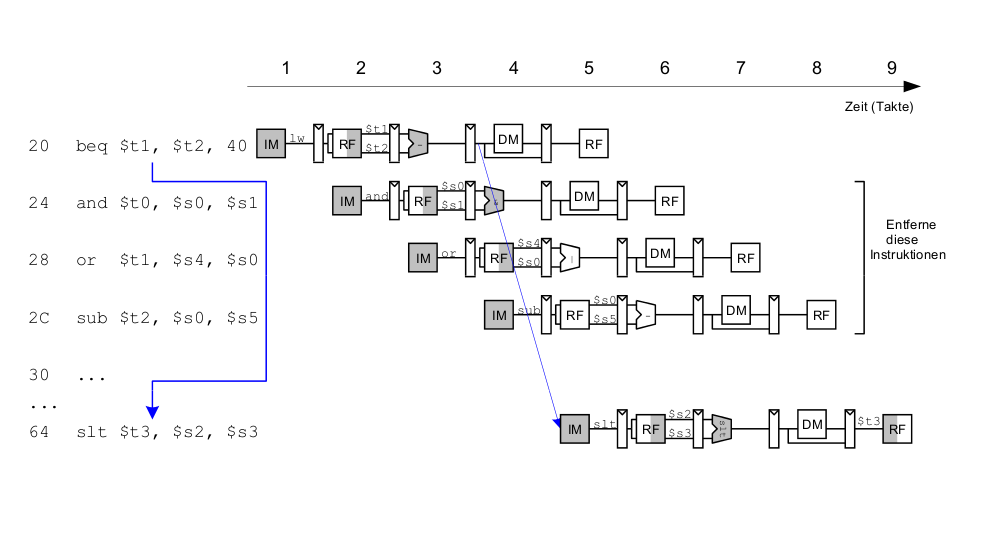
Beispiel: Auflösen von Control Hazard durch frühe Sprungentscheidung
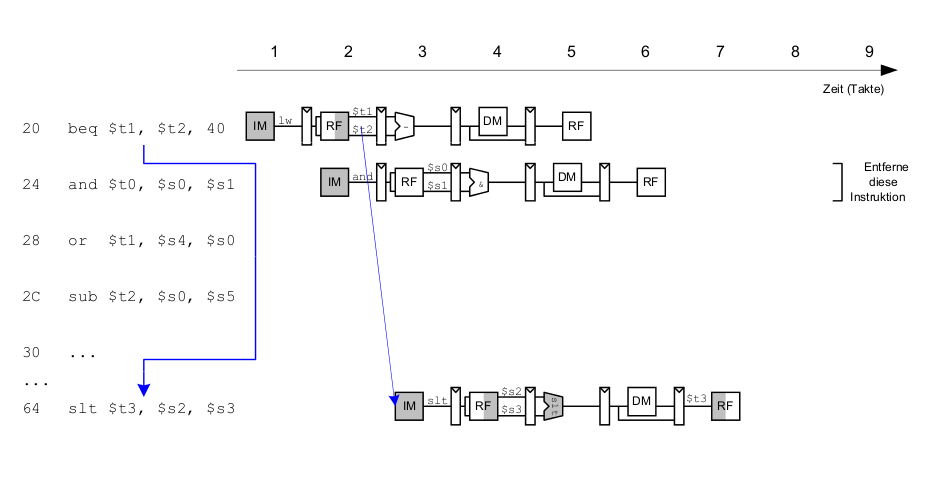
Control Hazards: Ansatz "Frühere Sprungentscheidung"
Berücksichtige neue Data Hazards
Frühe Sprungentscheidung: Benötigt Logik für Forwarding und Stalling
- Forwarding-Logik:

- Stalling-Logik:

Orthogonaler Ansatz: Sprungvorhersage
Bei dem orthogonalen Ansatz der Sprungvorhersage versucht man vorherzusagen, ob ein Sprung genommen wird. Danach können die Instruktionen von der richtigen Stelle geholt werden.
Man kann davon ausgehen, dass Rückwärtssprünge genommen werden, da diese hauptsächlich in Schleifen verwendet werde. Dafür wird eine Historie geführt. In dieser wird gespeichert, ob der Sprung die letzten Male genommen wurde. Denn war dies der Fall, dann ist die Wahrscheinlichkeit groß, dass er wieder genommen wird.
Eine gute Vorhersage reduziert die Zahl der Srpünge, die einen Flush der Pipeline erforderlich machen.
Beispiel: Rechenleistung des Pipelined-Prozessors
Idealerweise wäre natürlich CPI = 1.
Manchmal treten aber Stalls auf. Diese treten durch Lage- und Verzweigungsfehler auf.
SPECint 2000 benchmark:
- 25% loads
- 10% stores
- 11% branches
- 2% jumps
- 52% R-type
Wir machen folgende Annahmen:
- 40% der geladenen Daten werden gleich in der nächsten Instruktion gebraucht
- 25% aller Verzweigeungen werden falsch vorhergesagt
- Alle Sprünge erzeugen eine zu entfernende (flush) Instruktion
Wie hoch ist der durchschnittliche CPI-Wert?
- Lade/Verzweigungsinstruktionen haben CPI = 1 ohne Stall, = 2 mit Stall. Also:
 = 1 (0,6) + 2 (0,4) = 1.4
= 1 (0,6) + 2 (0,4) = 1.4
 = 1 (0,75) + 2 (0,25) = 1.25
= 1 (0,75) + 2 (0,25) = 1.25
Durchschnittlieche CPI = (0,25)(1,4)+(0,1)(0,1)+(0,11)(1,25)+(0,02)(2,0)+(0,52)(1,0) = 1,15
Beispiel: Rechenleistung des Pipelined-Prozessors
- Kritischer Pfad des Pipelined-Prozessors:

Beispiel: Rechenleistung des Pipelined-Prozessors
Wir führen nun 100 Milliarden Instruktionen auf einem Pipelined-MIPS-Porzessor aus.
Dabei haben wir:





Wiederholung: Ausnahmebehandlung (exceptions)
Exceptions entstehen durch einen außerplanmäßigen Aufruf der Ausnahmebehandlungsroutine. Dies wird verursacht durch:
- Hardware, auch genannt Interrupts, z.B. Tastatur, Netzwerk, ...
- Software, auch genannt Traps, z.B. unbekannte Instruktion, Überlauf, Teilen-durch-Null, ...
Wenn eine dieser Ausnahmen auftritt, dann wird:
- die Ursache für die Ausnahme im Cause Register gespeichert
- zur Ausnahmebehandlungsroutine bei 0x80000180 gesprungen
- ins Programm zurückgekehrt (über das EPC Register)
Beispiel für Ausnahme
Register für Ausnahmebehandlung
Die Register für die Ausnahmebehandlung sind nicht Teil des regulären MIPS Registerfelds.
Cause
- Speichert die Ursache der Ausnahme
- Koprozessor 0, Register 13
EPC (Exception PC)
- Speichert den PC-Stand, an dem die Ausnahme auftrat
- Korpozessor 0, Register 14
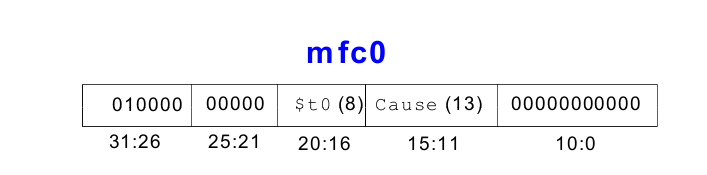
Befehl: "Move from Coprozessor 0"
mfc0 $t0, Cause
Dies überträgt den aktuellen Wert von Cause nach $t0.
Auswahl von Ausnahmeursachen
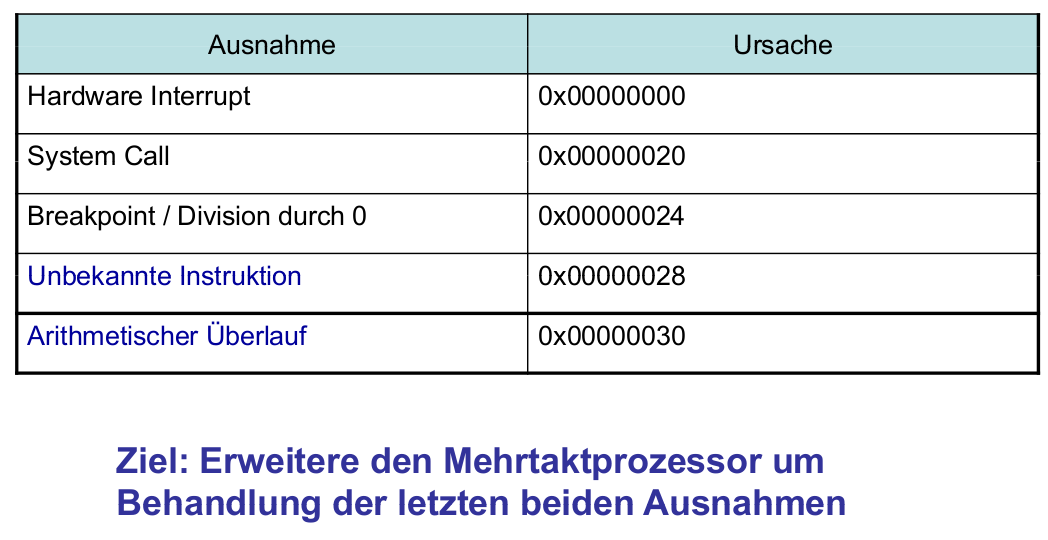
Hardware für Ausnahmebehandlung EPC und Cause
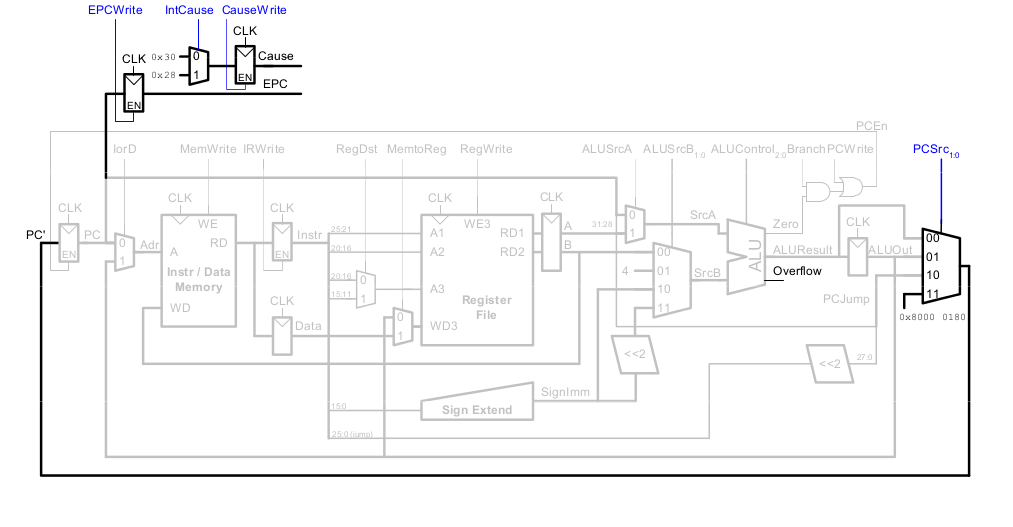
Hardware für Ausnahmebehandlung : mfc0
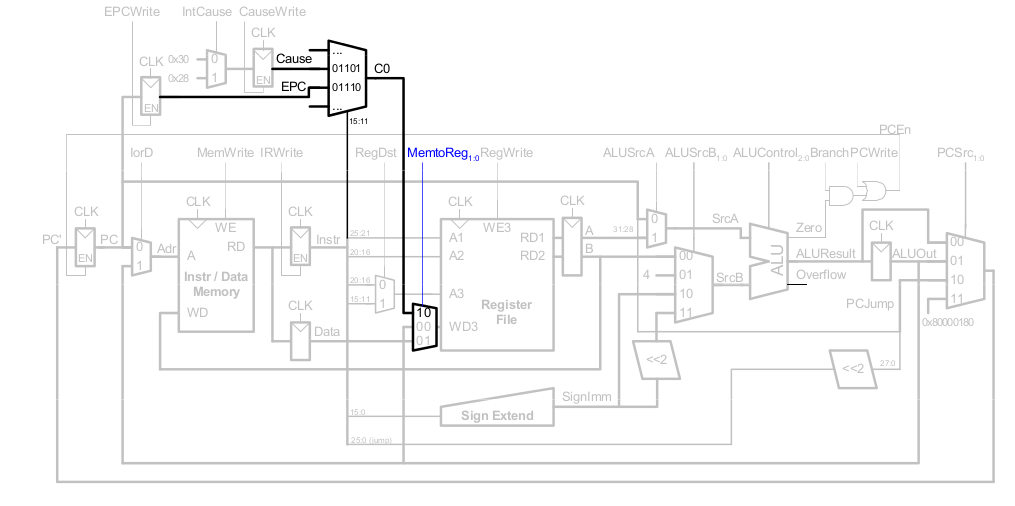
Steuerwerk - FSM erweitert um Ausnahmen
Weiterführende Themen der Mikroarchitektur
Weitere Themen in der Mikroarchitektur sind:
- Tiefe Pipelines
- Sprungvorhersage
- Superskalare Prozessoren
- Out of Order-Prozessoren
- Umbenennen von Registern
- SIMD (single instruction multiple data)
- Multithreading
- Multiprozessoren
Tiefe Pipelines
Üblicherweise beträgt die Tiefe einer Pipeline 10-20 Stufen. Es gibt aber auch Ausnahmen, wie Fehlkonstruktionen (z.B. Intel P4, mit mehr als 30 Stufen). Für anwendungsspezifische Spezialprozessoren gilt diese Konvention nicht. Diese können gegebenenfalls auch hunderte von Stufen haben.
Grenzen für die Pipeline-Tiefe sind gegeben durch:
- Pipeline Hazards
- zusätzlichen Zeitaufwand für sequentielle Schaltungen
- elektrische Leistungsaufnahme und Energiebedarf
- Kosten
Sprungvorhersage
Ein idealer Pipelined-Prozessor hat eine CPI von 1. Durch Fehler bei der Sprungvorhersage, erhöht% sich die CPI.
Die statische Sprungvorhersage prüft, ob die Sprungrichtung vorwärts oder rückwärts ist. Falls rückwärts gesprungen wird, sagt dies "Springen" vorher, ansonsten "Nicht springen".
Die dynamische Sprungvorhersage führt eine Historie der letzten (einigen hundert) Verzweigungen im Branch Target Buffer und speichert dabei:
- das Sprungziel
- und, ob der Sprung das letzte Mal / die letzten Male genommen wurde.
Beispiel: Sprungvorhersage
add $s1, $0, $0 # sum = 0
add $s0, $0, $0 # i = 0
addi $t0, $0, 10 # $t0 = 10
for:
beq $s0, $t0, done # falls i == 10, springe
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # inkrementiere i
j for
done:
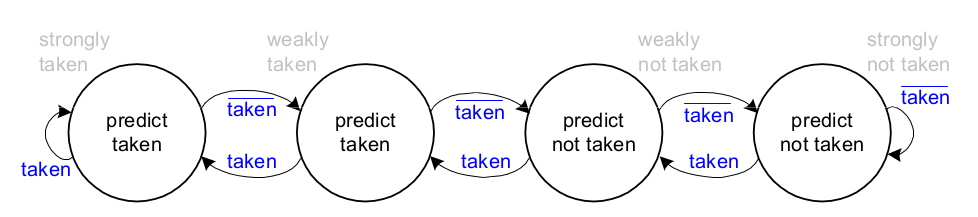
1-Bit Sprungvorhersage
Die 1-Bit Sprungvorhersage speichert, ob die Verzweigung das letzte Mal %blue&genommen wurde und sagt genau dieses Verhalten für das aktuelle Mal vorher.
Fehlervorhersagen
Sie wird einmal beim Austritt aus der Schleife beim Schleifenende das Falsche vorhersagen und demnach auch wieder, beim erneuten Eintritt in die Schleife.
add $s1, $0, $0 # sum = 0
add $s0, $0, $0 # i = 0
addi $t0, $0, 10 # $t0 = 10
for:
beq $s0, $t0, done # falls i == 10, springe
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # inkrementiere i
j for
done:
2-Bit Sprungvorhersage
Die 2-Bit Sprungvorhersage macht nur beim letzten Sprung aus der Schleife heraus eine falsche Vorhersage.
add $s1, $0, $0 # sum = 0
add $s0, $0, $0 # i = 0
addi $t0, $0, 10 # $t0 = 10
for:
beq $s0, $t0, done # falls i == 10, springe
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # inkrementiere i
j for
done:
Superskalare Mikroarchitektur
Superskalare Mikroarchitektur bedeutet, dass mehrere Instanzen des Datenpfades mehrere Instruktionen gleichzeitig ausführen. Abhängigkeiten zwischen den Instruktionen erschweren die parallele Ausführung.
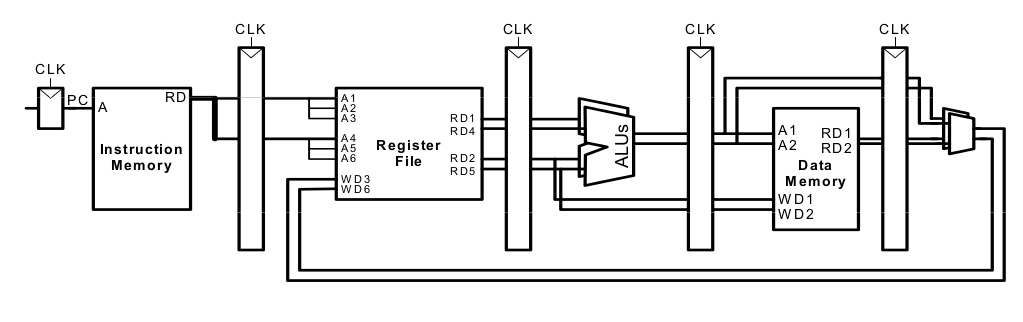
Beispiel: Superskalare Ausführung
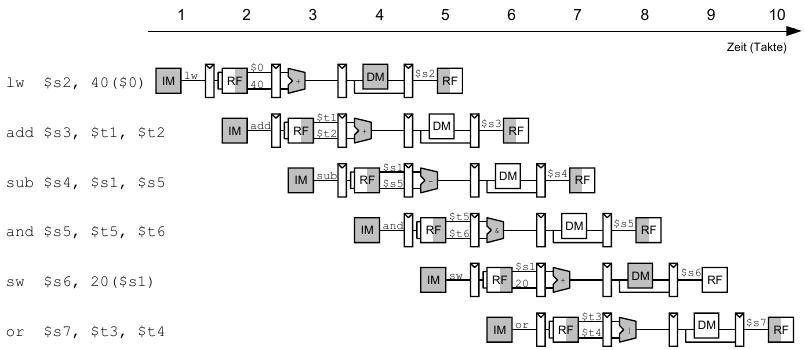
lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 and $t2, $s4, $t0 or $t3, $s5, $s6 sw $s7, 80($t3)
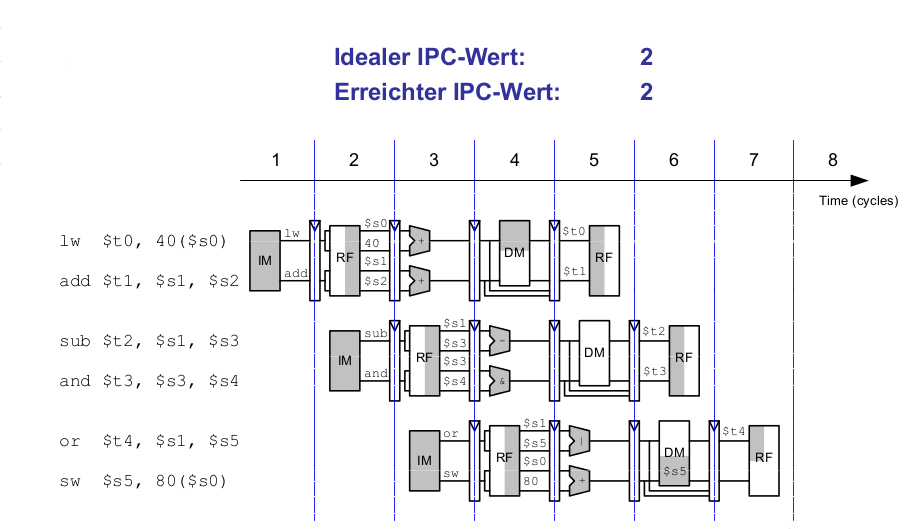
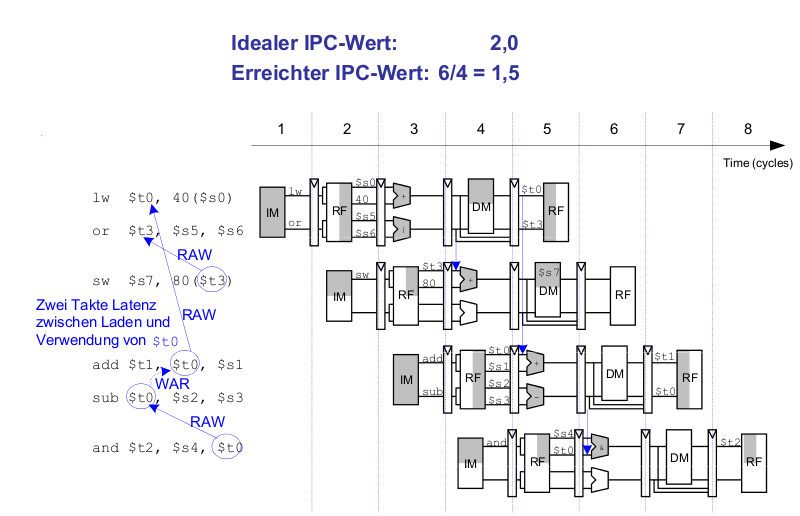
Beispiel: Superskalare Ausführung mit Abhängigkeiten
lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 and $t2, $s4, $t0 or $t3, $s5, $s6 sw $s7, 80($t3)
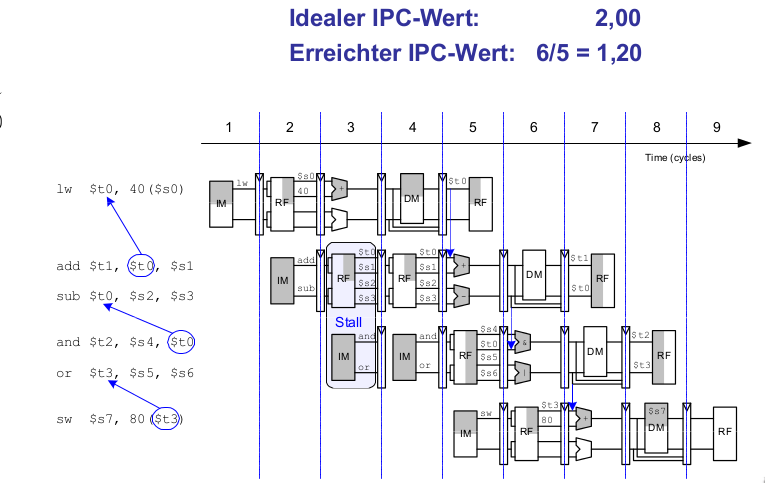
Out of Order-Mikroarchitektur
Die Out of Order-Mikroarchitektur kann die Ausführungsreihenfolge von Instruktionen umsortieren. Dabei sucht sie im Voraus nach parallel startbaren Instruktionen und startet diese in beliebiger% Reihenfolge, solange dadurch keine Abhängigkeiten verletzt werden.
Es gibt folgende Abhängigkeiten:
- RAW (read after write)
- WAR (write after read, anti-dependence)
- WAW (write after write)
Parallelismus auf Instruktionsebene (instruction level parallelism, ILP)
- Die Anzahl von parallel startbaren Instruktionen (in der Regel weniger als 3)
Scoreboard
- eine Art Tabelle im Prozessor
- es verwaltet
Beispiel: Out of Order-Mikroarchitektur
lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 and $t2, $s4, $t0 or $t3, $s5, $s6 sw $s7, 80($t3)
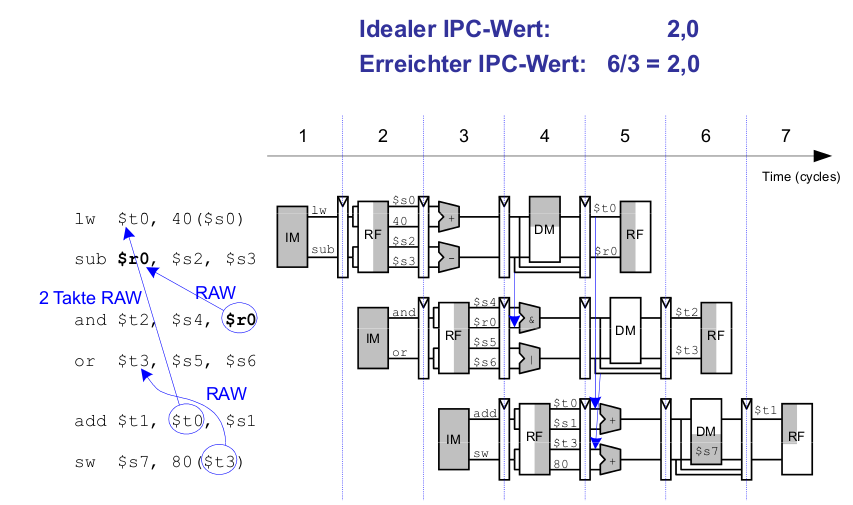
Umbenennen von Registern
lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 and $t2, $s4, $t0 or $t3, $s5, $s6 sw $s7, 80($t3
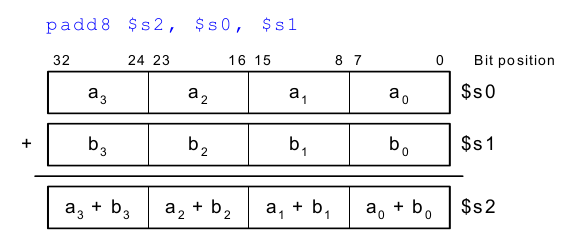
SIMD
SIMD steht für Single Instruction Multiple Data.
Das bedeutet, dass eine Instruktion auf mehrere Datenelemente gleichzeitig angewendet wird. Dies wird oft im Graphik- und Multimediabereich verwendet. Dabei werden oft schmale arithmetische Operationen ausgeführt. Dies nennt man auch gepackte Arithmetik. Ein Beispiel ist das gleichzeitige Addieren von vier Bytes.
Dafür muss die ALU verändert werden. Es gibt keinen Übertrag mehr zwischen einzelnen Bytes.
Fortgeschrittene Mikroarchitekturtechniken
Multithreading
- wird zum Beispiel in der Textverarbeitung verwendet
- Threads (parallel laufende, weitgehend unabhängige Instruktionsfolgen):
Multiprozessoren
- Haben viele weitgehend unabhängige Prozessoren auf einem Chip
- Sind heute am weitesten verbreitet in Grafikkarten (Hunderte von Prozessoren)
Multithreading
Prozesse sind auf dem Computer gleichzeitig laufende Programme wie z.B. der Web-Browser, Musik im Hintergrund, Textverarbeitung.
Ein Thread ist die parallele Ausführung als Teil eines Programmes. Ein Prozess kann mehreren Threads enthalten.
In konventionellem Prozessor:
- wird jeweils ein Thread ausgeführt
- Wenn eine Thread-Ausführung einen Stall% hat (z.B. weil sie auf den Speicher warten muss)
- Alle Threads laufen scheinbar gleichzeitig
Multithreading auf Mikroarchitekturebene
Beim Multithreading auf Mikroarchitekturebene haben wir mehrere Instanzen des Architekturzustandes im Prozessor. Damit sind mehrere Threads nun gleichzeitig% aktiv.
- Sobald ein Thread stalled wird sofort ein anderer gestartet
- Kein Sichern/Laden von Architekturzuständen mehr
- Falls ein Thread nicht alle Recheneinheiten ausnutzt, kann dies ein anderer Thread tun.
Das erhöht nicht den Grad an ILP (instruction-level parallelism) innerhalb eines Threads! Es erhöht aber den Durchsatz des Gesamtsystems mit mehreren Threads.
Multiprozessoren
Als Multiprozessoren bezeichnet man mehrere unabhängige Prozessorkerne mit einem dazwischenliegenden Kommunikationsnetz. Dabei gibt es verschieden Arten von Multiprocessing:
- Symmetric multiprocessing (SMT): mehrere gleiche Kerne mit einem gemeinsamen Speicher
- Asymmetric multiprocessing: unterschiedliche Kerne für unterschiedlieche Aufgaben.
- Clusters: Jeder Kern hat seinen eigenen Speicher.
